layout: post title: “NLP NMT综述” category: [Machine Learning] tags: []
NMT = neural machine translation
分类
- 多语言/领域NMT & 单语言/领域NMT
- 自回归NMT/非自回归NMT
- word/character level NMT
- 实时翻译/全句翻译
单语言NMT
经典模型是transformer: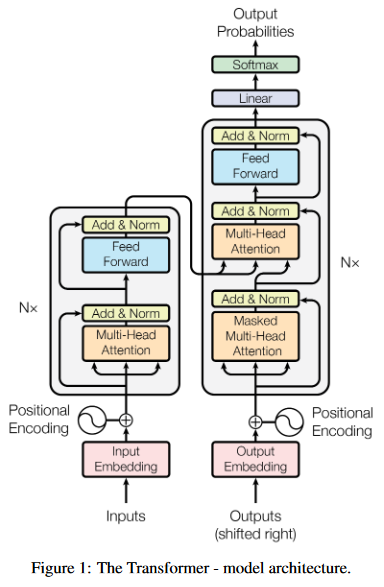
特点是:
- 每个NX代表一个完整的一层
- Encoder每层有2个sublayer,分别是ATT和FNN
- Decoder每层比Encoder多一层masked-ATT
- 每个sublayer之后都有Add&Norm
- Sublayer之间是残差网络
transformer的改进:
- 新的attention function,使用scaled dot-product作为alignment score。
- a multi-head attention modlule,使得NMT模型可以jointly attend to information from different representations at different positions。
多语言NMT
多语言NMT是指在一个模型中完成多对语言之间的翻译,具体可以分为一对多、多对一、多对多。
多语言NMT要解决的问题有:
- 单个语言的翻译性能不如单语言模型
- zero-shot问题。多语言NMT使得zero-shot翻译成为可能,但它的zero-shot翻译质量并不好。
提升语言翻译性能的方法
- 每个语言都有对应的encoder/decoder
例如:
一对多翻译,共享encoder
多对多翻译,多个语言共享attention mechanism
缺点:scalability受到限制。
- 把不同语言映射到同一个表示空间
例如:
with a target language symbol guiding the translation direction
缺点:
忽略了不同语言的linguistic diversity
- 在2的基础上,加入“语言的linguistic diversity”的考虑
例如:
reorganizing parameter sharing
designing language-specific parameter generator
decoupling multilingual word encoding
解决zero-shot问题的方法
多语言NMT处理zero-shot数据时(相对于pivot-based模型)会出现“off-target translation问题”,即翻译成一个错误的语言。
出现问题的原因:
- missing ingredient problem
- spurious correlation issue
解决方法:
- 跨语言正则化
- generating artificial parallel data with backtranslation
字符级NMT
Encoder:CNN层 + max pooling层 + highway层 + attention
Decoder:每次生成一个Character
在多语言场景中,字符级NMT非常有用,表现在:
- 两种语言有几乎相同的字符表,例如French和Spanish
- 两个差别较大的语言映射到一个共同的字符表,例如latinzing Russian和Chinese
transformor + 字符级 效果也不错。
自回归模型
target sentence的每个output token都与之前的output token有关,因此token是一个一个产生的。
生成长度为n的output需要经过n次迭代。
非自回归模型(NAT)
NAT,Non-Autogressive Machine Translation
不考虑sequential condition dependency,并行生成输出
时间复杂度:O(n) -> O(k)
优点:速度大幅提升
缺点:性能下降
原理:knowledge distillation,用于sequence-level distilled outputs
主要研究方向:缩小NAT与AT之间的性能差距
一些提升NAT性能的方法:
- takes a copy of the encoder input x as the decoder input, and trains a fertility predictor to guide the copy procedure
- generate the target sentence by interatively refining the current translation
- extra loss function
- change the generation order:左->右 ==》 tree-based
- multi-iteration refinements
- rescoring with 自回归模型
- aligned cross entropy/latent alignment mode(SOTA)
Masked 语言模型(BERT)
把输入序列的subset tokens用MASK代替,通过residual tokens推断missing tokens
[?] Maksed LM与transformer encoder是什么关系?
Energy-based model:
训练一个actor网络来控制AT的hidden state
[?] 这个模型没看懂,ACL.2020.251
实时翻译
基本模型:prefix-to-prefix framework
基于部分源句做预测
policy: wait k policy