多任务学习\citep{caruana93a}是通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方式。
[success]
y是一个向量。有n个task就是n*1的向量。如果一个样本只有部分标记,对某些task,它的标记不知道。计算loss时不要计算这一项即可。
multi-task与softmax的区别:
mult-task的y可以有多个1。
softmax的y只有1个1。
正如额外的训练样本能够将模型参数推向具有更好泛化能力的值一样,当模型的一部分被多个额外的任务共享时,这部分将被约束为良好的值(如果共享合理),通常会带来更好的泛化能力。
[success] 什么时候multi-task有意义?
(1)可以共用低层次特征
(2)每个任务的数据量很接近
(3)如果专注于其中一个Task,那么其它task的总数应该比这个task的样本多得多。
什么时候multi-task比single-task效果差?
神经网络不够大。
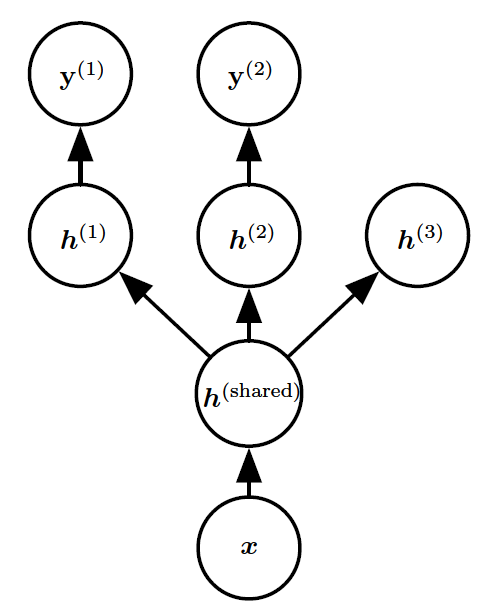
\figref{fig:chap7_multi_factor_output}展示了多任务学习中非常普遍的一种形式,其中不同的监督任务(给定预测)共享相同的输入以及一些中间层表示,能学习共同的因素池。 该模型通常可以分为两类相关的参数:
[success] 模型的共享包含连续多个layer的全部unit以及它们对应的参数
- 具体任务的参数 (只能从各自任务的样本中实现良好的泛化)。如\figref{fig:chap7_multi_factor_output}中的上层。
- 所有任务共享的通用参数(从所有任务的汇集数据中获益)。如\figref{fig:chap7_multi_factor_output}中的下层。
因为共享参数,其统计强度可大大提高(共享参数的样本数量相对于单任务模式增加的比例),并能改善泛化和泛化误差的范围\citep{baxter95a}。 当然,仅当不同的任务之间存在某些统计关系的假设是合理(意味着某些参数能通过不同任务共享)时才会发生这种情况。
从深度学习的观点看,底层的先验知识如下:\emph{能解释数据变化(在与之相关联的不同任务中观察到)的因素中,某些因素是跨两个或更多任务共享的。}
[success]
multi-task不如迁移学习使用频率高。
常用于CV的物体检测问题。
李宏毅补充
多任务模型的结构:
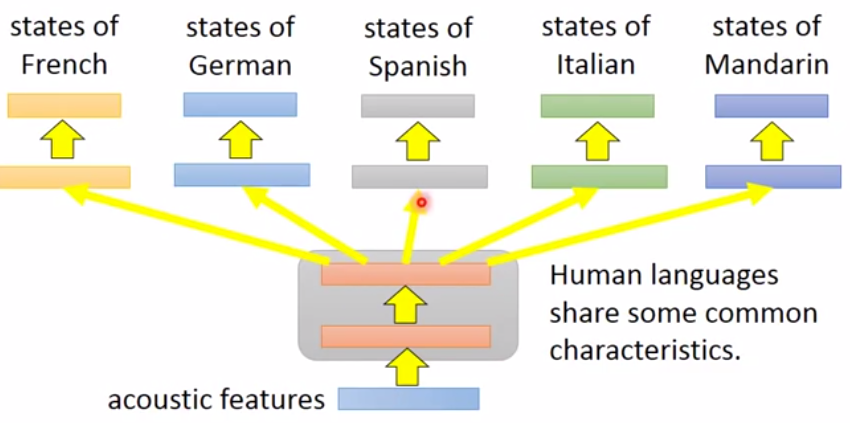
多任务模型的一种应用:
多语言的语言辨识,同时辨识多种语言。