反向传播算法非常简单。 为了计算某个标量关于图中它的一个祖先的梯度,我们首先观察到它关于的梯度由给出。 然后,我们可以计算对图中的每个父节点的梯度,通过现有的梯度乘以产生的操作的Jacobian。 我们继续乘以Jacobian,以这种方式向后穿过图,直到我们到达。 对于从出发可以经过两个或更多路径向后行进而到达的任意节点,我们简单地对该节点来自不同路径上的梯度进行求和。
[success]
6.5.3中的例子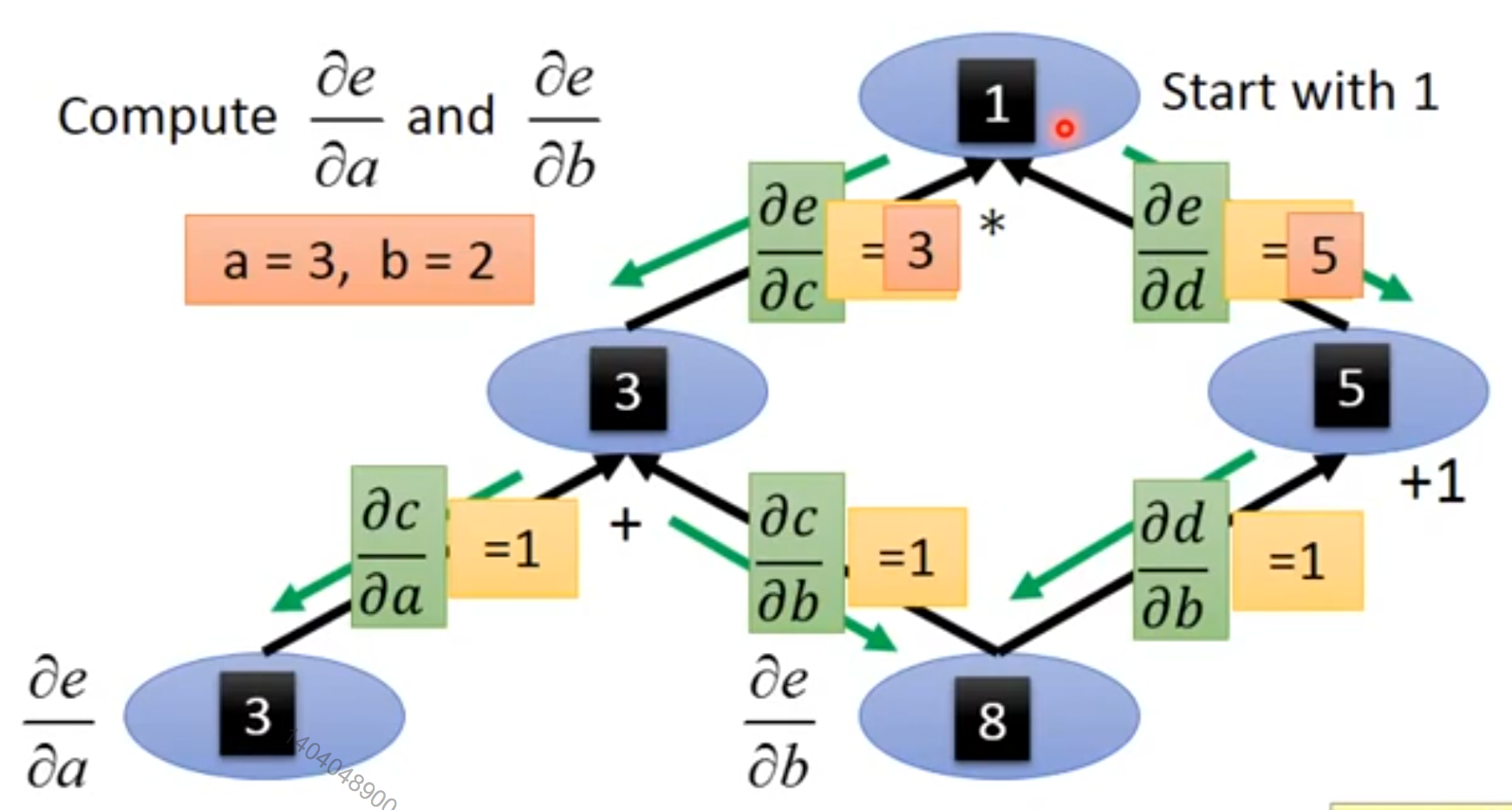
更正式地,图中的每个节点对应着一个变量。 为了实现最大的一般化,我们将这个变量描述为一个张量。 张量通常可以具有任意维度,并且包含标量、向量和矩阵。
我们假设每个变量与下列子程序相关联:
get_operation():它返回用于计算的操作,代表了在计算图中流入的边。 例如,可能有一个Python或者C++的类表示矩阵乘法操作,以及get_operation函数。 假设我们的一个变量是由矩阵乘法产生的,。 那么,get_operation()返回一个指向相应C++类的实例的指针。
[success] 返回get_operation函数的指针
get_consumers():它返回一组变量,是计算图中的子节点。
get_inputs():它返回一组变量,是计算图中的父节点。
每个操作op也与bprop操作相关联。
[warning] bprop操作?
该bprop操作可以计算如式6.47所描述的Jacobian向量积。
[info] 公式6.47:
这是反向传播算法能够实现很大通用性的原因。
[warning] [?] [?] 这一段看不懂
每个操作负责了解如何通过它参与的图中的边来反向传播。 例如,我们可以使用矩阵乘法操作来产生变量。 假设标量关于的梯度是。 矩阵乘法操作负责定义两个反向传播规则,每个规则对应于一个输入变量。 如果我们调用bprop方法来请求关于的梯度,那么在给定输出的梯度为的情况下,矩阵乘法操作的bprop方法必须说明关于的梯度是。
[success]
类似的,如果我们调用bprop方法来请求关于的梯度,那么矩阵操作负责实现bprop方法并指定希望的梯度是。
反向传播算法本身并不需要知道任何微分法则。
它只需要使用正确的参数调用每个操作的bprop方法即可。
正式地,op.bprop(inputs, X, G)必须返回
[success]
op.bprop(inputs, X, G)用于计算
第一项是
第二项是
这只是如公式6.47所表达的链式法则的实现。 这里,inputs是提供给操作的一组输入,op.f是操作实现的数学函数,是输入,我们想要计算关于它的梯度,是操作对于输出的梯度。
op.bprop方法应该总是假装它的所有输入彼此不同,即使它们不是。 例如,如果mul操作传递两个来计算,op.bprop方法应该仍然返回作为对于两个输入的导数。 反向传播算法后面会将这些变量加起来获得,这是上总的正确的导数。
反向传播算法的软件实现通常提供操作和其bprop方法,所以深度学习软件库的用户能够对使用诸如矩阵乘法、指数运算、对数运算等等常用操作构建的图进行反向传播。 构建反向传播新实现的软件工程师或者需要向现有库添加自己的操作的高级用户通常必须手动为新操作推导op.bprop方法。
反向传播算法的正式描述参考算法6.5。
{% raw %}
<!-- % alg 6.5 -->
\begin{algorithm}[ht]
\caption{反向传播算法最外围的骨架。
这部分做简单的设置和清理工作。
大多数重要的工作发生在\alg?的子程序{\tt build\_grad}中。
}
\begin{algorithmic}
\REQUIRE {% math_inline %}\Bbb T{% endmath_inline %},需要计算梯度的目标变量集
\REQUIRE {% math_inline %}G{% endmath_inline %},计算图
\REQUIRE {% math_inline %}z{% endmath_inline %}, 要微分的变量
\STATE 令 {% math_inline %}G'{% endmath_inline %} 为{% math_inline %}G{% endmath_inline %}剪枝后的计算图,其中仅包括{% math_inline %}z{% endmath_inline %}的祖先以及{% math_inline %}\Bbb T{% endmath_inline %}中节点的后代。
\STATE 初始化 {\tt grad\_table},它是关联张量和对应导数的数据结构。
\STATE {% math_inline %}{\tt grad\_table}[z] \leftarrow 1{% endmath_inline %}
\FOR{{% math_inline %}V{% endmath_inline %} in {% math_inline %}\Bbb T{% endmath_inline %}}
\STATE {% math_inline %}{\tt build\_grad}(V, G, G', {\tt grad\_table}){% endmath_inline %}
\ENDFOR
\STATE Return {\tt grad\_table} restricted to {% math_inline %}\Bbb T{% endmath_inline %}
\end{algorithmic}
\end{algorithm}
\begin{algorithm}[ht]
\caption{反向传播算法的内循环子程序{% math_inline %}{\tt build\_grad}(V, G, G', {\tt grad\_table}){% endmath_inline %},
由\alg?中定义的反向传播算法调用。
}
\begin{algorithmic}
\REQUIRE {% math_inline %}V{% endmath_inline %},应该被加到{% math_inline %}G{% endmath_inline %}和{\tt grad\_table}的变量。
\REQUIRE {% math_inline %}G{% endmath_inline %},要修改的图。
\REQUIRE {% math_inline %}G'{% endmath_inline %},根据参与梯度的节点{% math_inline %}G{% endmath_inline %}的受限图。
\REQUIRE {\tt grad\_table},将节点映射到对应梯度的数据结构。
\IF{{% math_inline %}\Bbb V{% endmath_inline %} is in {\tt grad\_table} }
\STATE Return {% math_inline %}{\tt grad\_table}[V]{% endmath_inline %}
\ENDIF
\STATE {% math_inline %}i \leftarrow 1{% endmath_inline %}
\FOR{{% math_inline %}C{% endmath_inline %} in {% math_inline %}{\tt get\_consumers}(V, G'){% endmath_inline %} }
\STATE {% math_inline %}{\tt op} \leftarrow {\tt get\_operation}(C){% endmath_inline %}
\STATE {% math_inline %}D \leftarrow {\tt build\_grad}(C, G, G', {\tt grad\_table}){% endmath_inline %}
\STATE {% math_inline %}G^{(i)} \leftarrow {\tt op.bprop}({\tt get\_inputs}(C, G'), V, D){% endmath_inline %}
\STATE {% math_inline %}i \leftarrow i + 1{% endmath_inline %}
\ENDFOR
\STATE {% math_inline %}G \leftarrow \sum_i G^{(i)}{% endmath_inline %}
\STATE {% math_inline %}{\tt grad\_table}[V] = G{% endmath_inline %}
\STATE 插入 {% math_inline %}G{% endmath_inline %} 和将其生成到{% math_inline %}G{% endmath_inline %}中的操作
\STATE Return {% math_inline %}G{% endmath_inline %}
\end{algorithmic}
\end{algorithm}
{% endraw %}
在第6.5.2节中,我们使用反向传播作为一种策略来避免多次计算链式法则中的相同子表达式。
由于这些重复子表达式的存在,简单的算法可能具有指数运行时间。
现在我们已经详细说明了反向传播算法,我们可以去理解它的计算成本。
如果我们假设每个操作的执行都有大致相同的开销,那么我们可以依据执行操作的数量来分析计算成本。
注意这里我们将一个操作记为计算图的基本单位,它实际可能包含许多算术运算(例如,我们可能将矩阵乘法视为单个操作)。
在具有个节点的图中计算梯度,将永远不会执行超过个操作,或者存储超过个操作的输出。
这里我们是对计算图中的操作进行计数,而不是由底层硬件执行的单独操作,所以重要的是要记住每个操作的运行时间可能是高度可变的。
例如,两个矩阵相乘可能对应着图中的一个单独的操作,但这两个矩阵可能每个都包含数百万个元素。
我们可以看到,计算梯度至多需要的操作,因为在最坏的情况下,前向传播的步骤将在原始图的全部个节点上运行(取决于我们想要计算的值,我们可能不需要执行整个图)。
反向传播算法在原始图的每条边添加一个Jacobian向量积,可以用个节点来表达。
因为计算图是有向无环图,它至多有条边。对于实践中常用图的类型,情况会更好。
大多数神经网络的代价函数大致是链式结构的,使得反向传播只有的成本。
这远远胜过简单的方法,简单方法可能需要在指数级的节点上运算。
这种潜在的指数级代价可以通过非递归地扩展和重写递归链式法则公式6.53来看出:
由于节点到节点的路径数目可以关于这些路径的长度上指数地增长,所以上述求和符号中的项数(这些路径的数目),可能以前向传播图的深度的指数级增长。 会产生如此大的成本是因为对于,相同的计算会重复进行很多次。 为了避免这种重新计算,我们可以将反向传播看作一种表填充算法,利用存储的中间结果来对表进行填充。 图中的每个节点对应着表中的一个位置,这个位置存储对该节点的梯度。 通过顺序填充这些表的条目,反向传播算法避免了重复计算许多公共子表达式。 这种表填充策略有时被称为动态规划。