1. Linear Unit解决二分类问题的局限性
许多任务需要预测二值型变量y的值。
具有两个类的分类问题可以归结为这种形式。
此时最大似然的方法是定义y在x条件下的Bernoulli分布。
[success] 问:什么是“y在x条件下的Bernoulli分布”?
答:
P(y∣x)∼ϕ(y∣x;p)P(y=1∣x)=pP(y=0∣x)=1−p
Bernoulli分布仅需单个参数来定义。
神经网络只需要预测P(y=1∣x)即可。
为了使这个数是有效的概率,它必须处在区间[0,1]中。
为满足该约束条件需要一些细致的设计工作。
假设我们打算使用线性单元,并且通过阈值来限制它成为一个有效的概率:
P(y=1∣x)=max{0,min{1,w⊤h+b}}
这的确定义了一个有效的条件概率分布,但我们无法使用梯度下降来高效地训练它。
当w⊤h+b处于单位区间外时,模型的输出对其参数的梯度都将为0。
梯度为0通常是有问题的,因为学习算法对于如何改善相应的参数不再具有指导意义。
[success] 梯度为0对如何改善算法参数没有指导意义。
Linear Unit不适用于解决二分类问题,这可能是Linear Unit + Cross Entropy做手写数据识别效果不好的原因。
相反,最好是使用一种新的方法来保证无论何时模型给出了错误的答案时,总能有一个较大的梯度。
这种方法是基于使用sigmoid输出单元结合最大似然来实现的。
2. 什么是Sigmoid Unit
sigmoid输出单元定义为
y^=σ(w⊤h+b)
这里σ是第3.10节中介绍的logistic sigmoid函数。
[success] logistic sigmoid
我们可以认为sigmoid输出单元具有两个部分。
首先,它使用一个线性层来计算z=w⊤h+b。
接着,它使用sigmoid激活函数将z转化成概率。
我们暂时忽略对于x的依赖性,只讨论如何用z的值来定义y的概率分布。
sigmoid可以通过构造一个非归一化(和不为1)的概率分布P~(y)来得到。
[success] 问:什么是“非归一化(和不为1)的概率分布”?
答:0≤P~(y)≤1,但不保证P~(y=0)+P~(y=1)=1。
我们可以随后除以一个合适的常数来得到有效的概率分布。
如果我们假定非归一化的对数概率对y和z是线性的,可以对它取指数来得到非归一化的概率。
[success] 问:什么是对数概率?
答:将概率取对数,这里是指logP~。
[warning] 为什么要假设logP~=yz,是否可以有别的假设?
我们然后对它归一化,可以发现这服从Bernoulli分布,该分布受z的sigmoid变换控制:
logP~(y)P~(y)P(y)P(y)=yz,=exp(yz),=∑y′=01exp(y′z)exp(yz),=σ((2y−1)z).
[success]
P~(y)是非归一化的概率分布。
P(y)是归一化后的Bernoulli分布。
基于指数和归一化的概率分布在统计建模的文献中很常见。
用于定义这种二值型变量分布的变量z被称为分对数。
3. Sigmoid Unit的交叉熵损失函数
这种在对数空间里预测概率的方法可以很自然地使用最大似然学习。
因为用于最大似然的代价函数是−logP(y∣x),代价函数中的log抵消了sigmoid中的exp。
[success] 问:交叉熵代价函数怎么抵消sigmoid中的exp?
答:根据上面的公式得:
pmodel(y=1)=σ(z)pmodel(y=0)=σ(−z)
将上面两个式子整合到一起:
pmodel(y∣x)=σ(z)y∗(1−logσ(z)1−y
将pmodel(y∣z)代入代价函数得:
J(x)=−ylogσ(z)−(1−y)(1−logσ(z))
根据求导链式法则:
∂z∂J=σ(z)−y
导数中消除了σ′这一部分,从而避免了饱和问题。
link证明了这一点
如果没有这个效果,sigmoid的饱和性会阻止基于梯度的学习做出好的改进。
我们使用最大似然来学习一个由sigmoid参数化的Bernoulli分布,它的损失函数为
J(θ)=−logP(y∣x)=−logσ((2y−1)z)=ζ((1−2y)z).
这个推导使用了第3.10节中的一些性质。
[success] ζ函数、softplut函数、相关性质
通过将损失函数写成softplus函数的形式,我们可以看到它仅仅在(1−2y)z取绝对值非常大的负值时才会饱和。
[success] ζ函数的形状如图所示:
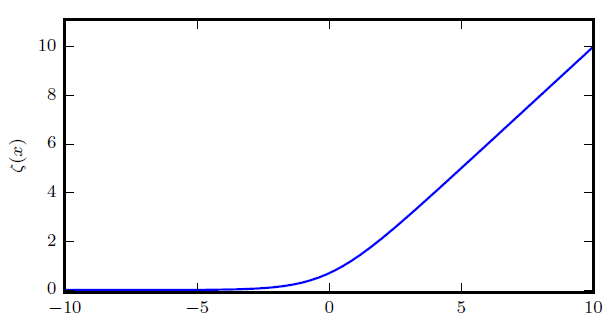
看图可知,只有(1-2y)z && |(1-2y)z|非常大时才会饱和。
因此饱和只会出现在模型已经得到正确答案时——当y=1且z取非常大的正值时,或者y=0且z取非常小的负值时。
[success]
- y=1 z>0 |z|非常大
- y=0 z<0 |z|非常大
但只有在已经得到正确答案时会满足这些条件。
当z的符号错误时,softplus函数的变量(1−2y)z可以简化为∣z∣。
当∣z∣变得很大并且z的符号错误时,softplus函数渐近地趋向于它的变量∣z∣。
对z求导则渐近地趋向于sign(z),所以,对于极限情况下极度不正确的z,softplus函数完全不会收缩梯度。
[success] 当z符号错误(对应为预测错误)时,不管错误多严重,导数始终为1或-1。
与之对比的是,如果使用二次代价函数,当错误很严重时unit会饱和。
这个性质很有用,因为它意味着基于梯度的学习可以很快地改正错误的z。
当我们使用其他的损失函数,例如均方误差之类的,损失函数会在σ(z)饱和时饱和。
sigmoid激活函数在z取非常小的负值时会饱和到0,当z取非常大的正值时会饱和到1。
这种情况一旦发生,梯度会变得非常小以至于不能用来学习,无论此时模型给出的是正确还是错误的答案。
因此,最大似然几乎总是训练sigmoid输出单元的优选方法。
4. 下溢问题
理论上,sigmoid的对数总是确定和有限的,因为sigmoid的返回值总是被限制在**开区间(0,1)∗∗上,而不是使用整个闭区间[0,1]的有效概率。
[warning] “sigmoid的对数总是确定和有限的”是什么意思?
在软件实现时,为了避免数值问题,最好将负的对数似然写作z的函数,而不是y^=σ(z)的函数。
[warning] [?] 这一段看不懂
如果sigmoid函数下溢到零,那么之后对y^取对数会得到负无穷。
[warning] y^不就是σ(z)吗?怎么会得到负无穷呢?