数据集
COCO数据集 - 训练集:
链接:https://pan.baidu.com/s/1x4s-AGkQ4hMxTGFZIkIdWw
提取码:38n7
COCO数据集 - 验证集:
链接:https://pan.baidu.com/s/1CNxeOz-fhcneLFa2t4-s4Q
提取码:xanc
COCO数据集 - 测试集:
链接:https://pan.baidu.com/s/1l-jh7lblStJUybjMkdellg
提取码:mm12
COCO数据集 - annotations: 链接:https://pan.baidu.com/s/1fM2m5xLBWAvJNyImFaLLBg 提取码:cdsu
ILSVRC2012数据集:
链接:https://pan.baidu.com/s/1Z8TO54qtrKZYumI8gEiAPg
提取码:p9q7
DL 学习路线
layout: post title: “Deep Learning自学路线” category: [Machine Learning] tags: []
入门
ML基础
学习笔记:http://windmissing.github.io/machine%20learning/2019-12/machine-learing-study-path.html ML和DL的很多概念是相通的,有一定的ML基础对学习DL是有帮助的。
数学基础
材料:《深度学习》 第一部分 应用数学与机器学习基础
作者:深度学习的三大开山鼻祖之一Yoshua Bengio
资源链接:https://pan.baidu.com/s/1GmmbqFewyCuEA7blXNC-7g 密码:6qqm
学习笔记:https://windmising.gitbook.io/mathematics-basic-for-ml/
DL入门
材料:Neural Networks and Deep Learning
作者:Hinton
资料链接:http://neuralnetworksanddeeplearning.com/index.html
学习笔记:https://windmising.gitbook.io/nielsen-nndl/
这是个英文材料,我一开始是拒绝的。但是因为没有找到很好的中文入门材料,只好去看了。看完这个材料的第一段,就对它路转粉。
虽然是英文材料,但是语言非常有亲和力,让人感觉看得很舒服,完全没有语言的隔阂感。
内容方面是“深入浅出”的典范。它非常浅湿,以致于其它书上都不屑于浪费笔墨的东西,它都认真地解释了一遍。它又非常很深度,有许多作者的思考和经验在里面。
对于完全没有DL的基础的同学,一定不要错过这个材料。
初级
理论
材料:《深度学习》第二部分 深度网络:现代实践
中文资源链接:https://pan.baidu.com/s/1GmmbqFewyCuEA7blXNC-7g 密码:6qqm
英文资源链接:http://www.deeplearningbook.org
学习笔记:https://windmissing.github.io/Bible-DeepLearning/
DL的经典材料。不要被这本书吓到了。其实这本书讲的内容还是比较直白的。只是涉及的内容太广,术语太多,用语太专业,让人看得比较费力。也正因为这些特点,被我拿来当入门材料,把DL的各个方面、各种术语混个眼熟。
材料:《李宏毅机器学习中文课程》、《机器学习及其深层结构化》
作者:李宏毅
资料链接:
https://www.bilibili.com/video/av9770190/?from=search&seid=17240241049019116161
https://www.bilibili.com/video/av9770302/?from=search&seid=9981051227372686627
学习笔记:跟《深度学习》的笔记记到一起了。
李宏毅老师的课程绝对走心。上课经验丰富。只知道怎么学生学习时的痛点在哪。知道怎么讲更容易让学生听懂。也知道学生听完后经常会问什么问题。
这两套视频课程非常多,看完需要耐心。我是挑着看的。以《深度学习》为主,这两套视频作为补充。
实践
材料:pytorch中文手册
link:https://pytorch-cn.readthedocs.io/zh/latest/
材料:深度学习工程师
作者:Ag
链接:网易云课堂
适合有一定理论基础。
编程笔记:https://windmissing.github.io/programming_basics_for_ML/
实践笔记:https://github.com/windmissing/DeepLearningPractise
我自己把《深度学习》中的一些算法用pytorch实现了一下,其实就是调库,看看效果。
如何定义CNN的超参数 答:尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数。以前是一些经典的模型。

Input层和Pool层没有参数,大部分参数在FC层。
Activation Size越来越小,如果下降太快可能会影响网络性能。
LeNet-5
论文:LeGun et at., 1998. Gradient-based learning applies to document recognition section II
- W减小,H减小,C增大。
- CONV -> POOL -> CONV -> POOL -> FC -> FC -> output,经典结构
- 使用sigmoid/tanh — 废弃
- 使用复杂的计算来处理POOL中的通道 — 当时性能限制,废弃
- 池化使用了非线性函数 — 废弃
AlexNet
论文:Krizhevsky et al., 2012. Image Net classification with deep convolutional neural networks
- 特征数量大。
- 能处理非常相似的基本模型。
- 使用ReLU
- 多GPU
- 局部响应归一化 — 不常用
VGG- 16
- 相对一致的结构
- 特征数量非常大

He et.al., 2015. Deep residual networks for image recognitisn
什么是残差网络
Residual Block
正常的网络层是这样的:
$$ \begin{aligned} z^{[l+1]} = W^{[l+1]}a^{[l]} + b^{[l]} \ a^{[l+1]} = g(z^{[l+1]}) \ z^{[l+2]} = W^{[l+2]}a^{[l+1]} + b^{[l+1]} \ a^{[l+2]} = g(z^{[l+2]}) \end{aligned} $$
残差块是这样的:
图中黑色的线称为main path,绿色的线称为short cut/skip connection。
公式的变化体现在最后一行:
$$ \begin{aligned} z^{[l+1]} = W^{[l+1]}a^{[l]} + b^{[l]} \ a^{[l+1]} = g(z^{[l+1]}) \ z^{[l+2]} = W^{[l+2]}a^{[l+1]} + b^{[l+1]} \ a^{[l+2]} = g(z^{[l+2]} + a^{[l]}) \end{aligned} $$
残差块使网络可以更深。网络深度与训练集性能的关系:
Residual Network

为什么残差网络有用?
$$ \begin{aligned} a^{l+2} &=& g(z^{l+2} + a^l) \ &=&g(W^{l+2}a^{l+1} + b^{l+2} + a^l) && (1) \ &=& g(a^l) && (2) \ &=& a^{l} && (3) \end{aligned} $$
(1) 由于L2 正则化的影响,W会shrink,假设此时W=0
(2) 假设g使用ReLU
(3) 根据以上公式$a^{L+2}$可以很容易地得到与a^l相同的结果。(性能不变)。因此在一个深的NN上增加一个residual block,至少不会对性能有坏处。
运气好的话,a^{l+2}能得到比$a^l$好的结果。(性能提升)
其它
因为$a^{l+2} = g(z^{l+2} + a^l)$使用残差块用的跳跃连接,要求使用same卷积。使$a^l$与z^{l+2}有相同的维度。
或者将$a^l$映射到$z^{l+2}$的大小:
$$ a^{l+2} = g(z^{l+2} + Wa^l) $$
Lin. et. al., 2013. Network in network
什么是1*1卷积
单通道场景中,1 * 1卷积看上去没什么用,相当于所有像素值乘以一个实数。
多通道场景中,1 * 1卷积是有用的。相当于对一个像素在所有通道上的点做一次全连接的计算,即一个像素在所有通道上的点与kernal做点乘,得到一个值。
1 * 1卷积又叫network in network
应用
(1)改变通道数
在不改变图像大小的情况下改变通道数。 例如:
$$ 28\times 28\times 192 * 32\text{个} 1\times 1\times 192 \rightarrow 28\times 28\times 32 $$
通过减少通道数减少计算量
(2)非线性变换
即使不改变通道数,可以用这种1 * 1卷积。相当于对原始数据做了一次非线性变换,使得可以学习更复杂的特征。
Szegedy. et. al., 2014. Going deeper with convolutions
Inception网络代替人工来确定卷积层中的过滤类型。或是决定是否需要创建卷积层或池化层。
Inception网络的原理
多种参数的组合

Inception网络不需要人为地决定使用哪个过滤器,或是否需要池化,而是由网络自行确定这些参数。
即:给网络添加这些参数的所有可能,然后把这些输出连结起来,让网络自己学习它需要怎样的参数,采用哪些过滤器的组合。
使用1*1卷积降低计算成本
未降低的计算成本
例如: $28\times 28 \times 192$,使用相同卷积,f=5,c=32,得到$28\times 28\times 32$,计算量(不是参数个数)为:
output中的点的个数 = 28 * 28 * 32
每个点计算一次filter = 5 * 5 * 192
一共需要约120M次乘法
改进的计算成本
$28\times 28 \times 192$,使用1*1卷积,c=16,得到$28\times 28\times 16$
$28\times 28 \times 16$,使用相同卷积,f=5,c=32,得到$28\times 28\times 32$
第一次卷积的计算量约为$28 \times 28 \times 16 \times 192 = 2.4M$,第二次卷积的计算量约为$28\times 28 \times 32 \times 5 \times 5 \times 16 = 10.0M$。
最后实现同的目标,这种方法只需要约12.4M次,为原来的十分之一。
例子中的$28\times 28\times 16$称为瓶颈层。
只要合理构建瓶颈层,既可以显著缩小表示层规模,又不会降低网络性能,从而节省大量计算。
Inception模块

图中2、3、4行的1*1卷积是为了通过构建瓶颈层缩小网络规模。
Inception网络

图中画红圈的都是Inception模块。
画绿圈的部分为基于隐藏层结果的输出。
多个输出是为了确保:隐藏层既用于特征计算,也用于预测结果。
Seq2Seq
Seq2Seq与Language Model都可以用于生成字符串,它们的区别是:LM是随机生成字符串,Seq2Seq是条件生成字符串。
Neural Translation
Sutskever el. at., 2014. Sequence to sequence learning with neural networks
Cho et. al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation
Image Captioning
Mao et. al., 2014 Deep Captioning with nultimodal returrent neural netowrks
Vinyals et al., 2014. Show and tell: Neural image caption generator
Kelvin Xu. al., 2015. Show, Attend and Tell: Neural Image Cpation Generation With Visual Attention
根据图像生成描述:AlexNet + Decoder
翻译模型
同一句输入可能得到不同的输出,怎么找到最好的输出?
已知$p(y) = P(y^t|x, y^1, y^2, \cdots, y^{t-1})$ 即怎么找到$y = (y^1, y^2, \cdots, y^{T_y})$,使得P(y|x)最大?
贪心搜索 greedy search
每个时刻t都选择t时刻p(y)最大的y,直至输出 <EOS>
缺点:每一步都选择概率最高的y,但最后句子的整体概率不一定是最高的。
例如:
Jane is visiting Africa in September.
Jane is going to visit Africa in September.
英语中going比visiting常见,因此P(Jane is visiting|x) < P(Jane is going),最后会得到第二句。
实际上整个句子来说,第一句比第二句好。
束搜索/定义搜索 beam search
- 根据$P(y^1|x)$选择最好的B个y1

- 对每个y1分别计算它与各种y2组合的概率。并找出其中概率最高的B组y1, y2

- 对B个y1y2串,用同样的方法找出B个概率最高的y1y2y3。
- 直至最后得到了
<EOS>。
当B=1时,beam search = greedy search
B大,则生成的句子可能更好,但计算代价更大。B小则反之。
产品中经常使用B=10。
在比赛或论文中,可能出现B=1000,3000等值,以得到更好的成绩。
BFS、DFS是精确搜索算法。
beam search是近似搜索算法/启发式搜索算法。
beam search的问题与改进
- 公式出现的$p(y) = P(y^t|x, y^1, y^2, \cdots, y^{t-1})$、P(y|x)等都是概率值,且值很少,对它们做连乘容易出现下溢。
解决方法:P -> log P - 句子概率 = 每个单词概率的乘积,并选择概率最大的句子。这样长句子肯定没优势,算法会倾向于选择较短的句子。
解决方法:log P -> $\frac{1}{T_y}\log P$
beam search的debug
例子:某一句的翻译
人工翻译:y = Jane visits Africa in September.
机器翻译:$\hat y$ = Jane visited Africa last September.
机器翻译改变了愿意,认为翻译得很差。
Debug: model由RNN(encoder + decoder)和beam search两部分组成
分别计算$P(y|x)$和$P(\hat y|x)$
如果$P(y|x) > P(\hat y|x)$,则认为beam search不对。
如果$P(y|x) < P(\hat y|x)$,则认为RNN不对。
评价翻译结果 - Bleu
Bleu = bilingual evaluation understudy = 双语评估替补
目的:当生成的字符串可以有多个答案时,评价生成字符串的好坏。
例如评价一个翻译句子的好坏。
Bleu Score用于各种文本生成的模型,但不用于语音识别。因为语音识别只有一个正确答案。
定义
- 句子正确翻译为reference:
reference 1: The cat is on the mat. reference 2:There is a cat on the mat. - 定义机器翻译结果为MT output:
MT output: The cat the cat on the mat. - 定义n-gram为连续n个单词组成的一个短语。
Bleu算法不考虑大小写,因此在本例中,
1-gram有:the, cat, on, mat
2-gram有:the cat, cat the, cat on, on the, the mat - 定义Count(n-gram)为n-gram在MT output中出现的次数。CountClip(n-gram)为n-gram在所有reference中出现最多的次数。
在本例中Count(n-gram)和CountClip(n-gram)分别为:
| n-gram | Count(n-gram) | CountClip(n-gram) |
|---|---|---|
| the | 3 | max(2, 1)=2 |
| cat | 2 | max(1,1)=1 |
| on | 1 | 1 |
| mat | 1 | 1 |
| the cat | 2 | 1 |
| cat the | 1 | 0 |
| cat on | 1 | 1 |
| on the | 1 | 1 |
| the mat | 1 | 1 |
- 定义$P_n$为n-gram的precision
$$ P_n = \frac{\sum_{\text{n-gram}\in \hat y}(\text{CountClip}(\text{n-gram}))}{\sum_{\text{n-gram}\in \hat y}(\text{Count}(\text{n-gram}))} $$
例如在本例中,
$$
\begin{aligned}
P_1 = \frac{2+1+1+1}{3+2+1+1} = \frac{5}{7} \
P_2 = \frac{1+0+1+1+1}{2+1+1+1+1} = \frac{4}{6}
\end{aligned}
$$
- 定义Bleu Score
以上求出来的各种n-gram的precision。需要用一个数值来代表所有的Pn。
$$ P = \text{BP} * \exp(\frac{1}{n}\sum_n P_n) $$
由于根据Pn公式,MT ouput短时更容易得高分。因此通过增加BP来调整。
BP = brevity penalty
$$
BP =
\begin{cases}
1, && \text{MT length} < \text{reference length} \
\exp(\frac{1 - \text{MT length}}{\text{reference length}}), && \text{otherwise}
\end{cases}
$$
BLEU是一个比较好的用单一实数来评价NMT的方法。加速了整个NMT领域的进程。也可以用于评价其它文件生成的结果。不用于语音,因为语音通常只有一个答案。
Seq2Seq模型存在的问题

先输入整个原文序列,再输出整个翻译序列。
事实上,如果原文序列很长,一次性记住全部内容是困难的。因此导致翻译结果不好。
改进方法:attention based模型,一次读入一部分,根据部分信息提供输出,然后再读入一些信息。
Bahdanau et, al., 2014 Neural machine translation by jointly learning to align and translate
注意力模型的结构
encoder
使用双向RNN来计算每个单词的特征。双向RNN的unit可以是GRU或LSTM或其它类型的Unit。
每个单词通过双向RNN会得到2个activition,分别定义为\overrightarrow{a^t}和\overleftarrow{a^t}。并用一个符号来表现这两个activation。
a^t = (\overrightarrow{a^t}, \overleftarrow{a^t})

decoder
decoder部分的结构和翻译模型是基本上一样的。

decoder使用某个context作为输入,context用向量C表示,是一个与encoder中的activation有关的向量。
注意力权重
关键在于怎样连接encoder与decoder。翻译模型使用顺序连接,先encoder,再decoder。
注意力模型使用注意力权重将encoder的activation和decoder的context联系到一起。
定义注意力权重$\alpha^{t1,t2}$为:当生成y的第t1个单词时,对原文第t2个词的注意力应该是多少?
$$
\begin{aligned}
\sum_{t2}\alpha^{t1,t2} = 1 \
C^{t1} = \sum_{t2}\alpha^{t1, t2} a^{t2}
\end{aligned}
$$
注意力模型的计算过程
注意$a$和$\alpha$的区别。
由于输入序列和输出序列是两个不同的序列,分别用于t1、t2表示输出序列和输入序列的时间步。
整体计算过程为:
$$
x \rightarrow a \rightarrow e \rightarrow \alpha \rightarrow C \rightarrow s \rightarrow y
$$

$x \rightarrow a$
Encoder
$a \rightarrow e$
根据t2时间步的Encoder输出和t1-1时间步的Decoder中间状态,计算出t1时间对t2时间的注意力。
可以看作是嵌入了一个简单的网络。
$e \rightarrow \alpha$
以及t2为维度为e作为归一化,使得归一伦后$\sum_{t2}\alpha^{t1,t2} = 1 $
$$
\alpha^{t1,t2} = \frac{\exp(e^{t1,t2})}{\sum_{t2}\exp(e^{t1,t2})}
$$
$\alpha \rightarrow C$
根据归一化后的注意力权重计算Decoder的输入。
$$
\begin{aligned}
C^{t1} = \sum_{t2}\alpha^{t1, t2} a^{t2}
\end{aligned}
$$
$C \rightarrow s$
Decoder
$s \rightarrow y$
输出
时间复杂度
注意力模型的时间复杂度为$O(n^3)$,复杂度有点高。
由于机器翻译的输入、输出通常不是会太,因此$O(n^3)$也是可以接受的。
任务描述
根据Ducument和Query生成Answer
Answer是提前定义好的, 要从这些答案中选择一个正确答案.
这是一个多分类问题
模型
Sainbayar ukhbaatar, 2015, End-to-End Momery Network
利用attention机制, 用较少的参数,训练出较好的效果.

过程
- 把Document中的每个句子转成一个bag of word向量,N个句子得到N个高维向量
- 降维,N个高维向量通过乘以一个矩阵得到N个低维向量x, 矩阵的内容是迭代学习得到的.
- 将Query转成向量q
- 计算q与x的match score,每个x对应一个score,定义为$\alpha$, match score为x与q的余弦相似度
- 根据$\alpha$对x做加权求和$\sum_i\alpha_i x_i$
- 5的结果和q一起进入一个DNN
- 由DNN产生answer
Attention-based Model进阶版
Sentence to vector can be jointly trained.
改进1
Document产生2个向量,分别是x和h。
第4步使用x计算match score,用于决定从哪些向量抽取信息。
第5步使用h生成最终被抽取的信息。$\sum_i\alpha_i h_i$
改进2 hopping
根据当前的结果生Extracted Information生成新的问题向量q
q = q + Extracted Information
基于新的q再计算答案
hopping可以做多次,hopping的次数可以是人为决定,也可以Machine自己决定ReasoNet。
改进3
Answer只由Extracted Information决定,q不进入DNN
背景
假设有这样一个闭包问题,要求输入所有的点,输出这组点的闭包点的顺时针序列.
这是一个Seq2Seq问题,但是用普通的Seq2Seq模型来做,存在这样一个问题.decoder部分是根据概率从一个集合中sample一个点作为输出.在这个问题中,集合就是输入的点集.但输入的点集是不是确定的,可能是50个点,也可能是100个点.因此无法训练decoder.
模型
解决方法:
在attention上做一些改进,让network动态地决定输出的set有多大.
具体方法为:去掉decoder,直接基于attention的结果作为输出.

应用
-
Summarization,相当于取出原文中的重要的词
原文中有些没见过的人名, 地名,在普通的Seq2Seq模型中无法处理这些人名地名. PointerNetwork可以直接从原文中抽取重要的词组成句子.
在网络中同时存在Seq2Seq attention和Pointer Network.并增加一个结点Pgen,用于决定这两条路的weight. 基于weight结合这两条路的结果. -
翻译
有些人名、地名不需要翻译,使用pointer Network机制从原文中拿出单词直接贴到output中
- Chat-Bot
直接从input中copy关键词放到output中
Recursive Network的结构
Recurrent Network VS Recursive Network
以情绪分类任务为例来说明Recurrent Network和Recursive Network的区别:
从图上看,把它称为递归网络更合适.
Note: x和h的维度必须相同.
Recursive Network中的f定义如下:
定义一:

定义二: Matrix-Vector Recursive Network
结构复杂但效果不好
把向量分为2部分,前面代表单词本身的含义,后面代表对其它单词的影响.
过程解释:
a被B影响得到一个结果, b被A影响得到另一个结果.两个结果合在一起,代表新向量的内容.
A和B结合在一起,代表新向量的影响力.
问: 设计f时,为什么认为向量的前面代表单词本身的含义,后面代表对其它单词的影响?
答: 不是因为向量有这样的含义所以这样设计网络.而是因为这样设计网络,训练的结构导致向量有这样的含义.
定义三: Tree LSTM

Recursive Network的应用
sentence relatedness

RNN的其它应用

(1)Many to Many问题,且Tx = Ty
(2)Many to One问题,文本分类
(3)One to Many问题,如Music生成
(4)Many to Many问题,且Tx <> Ty,例如机器翻译
总结:
many to one
输入 vector sequence,输出:one vector
例如:
文件的情绪分析
文本的关键词,30’00’’
many to many,output is shorter
输入输出都是vector sequence,输出的sequence更短。
例如:语音辨识,输入声音信号,输出字符序列
- 将声音信号切成小段,每段不超过0.01s
- 把每一小段声音转成一个向量。
- 根据每个向量输出一个字符。
- 通常好个向量输出同一个字符,需要把重复的字符去掉。

由于输入和输出的长度不同,不管训练还是预测,都会遇到一个问题。
训练时,多个向量输出同一个字符,如果把多余的字符去掉,但不会误伤叠词。
解决方法:增加一个为空的字符,只把为空的字符去掉。
预测时,某个向量的输出是真实字符还是空字符?
解决方法:CTC training,即穷举所有正确的可能。
many to many, no limitation
输入和输出都是序列,不知道序列的长短。
应用1:语言翻译
训练方法:
- 每输入一个英文单词,输出一个中文字符。
- 英文序列停止了,但中文序列继续输出。
- 在中文字符中增加一个停止字符。
- 当输出为停止字符时,停止输出。


应用2:语言A的声音信号 -> 语言B的文字
不需要经过A的文字作为中间转换。
用于语言A没有对应的文字的场景。
Beyond Sequence
应用:句法分析树
输入:序列
输出:语言结构树
使用seq2seq,而不是struct learning
sequence to sequence, Auto-encoder
-
用在文字上
普通的encoder算法会忽略单词的顺序,因而影响句子的理解。
Auto-encoder算法会考虑单词的顺序。
单层模型:
多层模型:
-
用在语音上
把长度不固定的语音片段转成长度固定的向量。
用处:语音搜索
问:怎样把语音变成向量?
答:encoder技术
问:怎样比较?
答:
通常把encoder和decoder一起训练
GRU VS Highway Netword
Highway Network基于GRU对Unit做了一些改进:
-
GRU

-
Highway Network Unit

主要改进为:
- 去掉 Input $x^t$和Output $y^t$,只有第一个Unit有Input,最后一个Unit有Output
- 输入$h^t$换成$a^{t-1}$
- 去掉reset gate,保证$a^{t-1}$一定能进入下一个step
Highway Network Unit的计算过程:
$$
\begin{aligned}
h’ = \sigma(W a^{t-1}) \
z = \sigma(W’ a^{t-1}) \
a^t = z \odot a^{t-1} + (1-z)\odot h’
\end{aligned}
$$
这相当于在layer方向增加gate,以达到使layer更深的目的。
如果只接将z设置成0.5,就成了残差网络。
Highway Network可以看作是Network自动学到要有多少hidden layer。
根据data决定实际使用几层layer。
CV 基础
Computer Vision Problems
- 图像分类问题:Image Classification,判断图像是不是汽车
- 图像定位分类问题:Image Classification With Localization,判断图像是不是一辆汽车,并标出洗车的位置
- 物体检测问题:检测图像中是否存在车子。如果有车子,标出洗车的位置。如果有多个车子,标出每个车子的位置。
- 风格迁移
- 人脸验证问题:
输入:图像,name/ID,输出:图像和name/ID是否对应 - 人脸识别问题:
输入:datasets, image
输出:image对应的name/ID

earlier layers:边缘检测
later layers
even later layers
问题描述
每张图像中最多只有一个较大的对象,且位于相对中间的位置。
要识别的目标有三类:pedestrain、car、motorcycle,分别对应c1, c2, c3
定义图像的左上角坐标为(0,0),右下角坐标为(1,1)。目标的中心点为bx, by,目标的大小为bh, bw。
定义标签y
定义一个训练集的label应该为1*8的向量,即:
$$
y = [p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3]^\top
$$
pc:图像中是否存在对象。pc为1时后面的值才有意义。
bx, by, bw, bh:对象的位置。
c1, c2, c3:是什么对象,三个数值只能有一个是1。
例如:
$$ \begin{aligned} y = [1, b_x, b_y, b_h, b_w, 0, 1, 0]^\top \ y = [0, ?, ?, ?, ?, ?, ?, ?]^\top \end{aligned} $$
?表示不care具体的值,不会在loss function中用到这些值。
定义损失函数
定义一个样本上的损失函数为:
$$ l = \begin{cases} MSE(pc, bx, by, bw, bh) + CrossEntropy(c1, c2, c3) && pc = 1 \ MSE(pc) && pc = 0 \end{cases} $$
Landmark Detection
landmark detection不是检测对象,而是检测某些特征点。
例如:
landmarks detection可用于表情识别、AR
目标检测
目标检测是计算机视觉中的重要任务,旨在定位并识别图像中的多个目标。
本章包含以下内容:
滑动窗口算法
- 使用图像分类算法判断一张图像是不是车
- 滑动窗口目标检测
以固定的步幅滑动窗口,遍历图像每个区域,相邻window会有overlap。
把这些剪裁后的小图像输入卷积网络。
对每个位置按0、1进行分类。 - 换一个更大的窗口,重复以上动作。不同size的window都需要遍历。
缺点:
(1)计算成本高
(2)如果减少window,可能会找不出目标
(3)如果分类器太简单,可能会使分类精度下降
Redom et. al., 2015. You Only Look Once: Unfied real-time object detection
这篇论文比较难。
Bounding Box
把原图像切成18 * 18的格子,每一个格子输出一个与目标定位算法相同的1 * 8的label。如果某个格子检测到对象,就把对象分配到中心点所在的格子。
输入:n_H * n_W * n_C
输出:19 * 19 * 8
虽然每个格子的输出结果与目标定位算法的输出结果相同,都能检测对象并精确地输出对象的中心点和边界。但是,不是对每一个格子跑一遍目标定位算法,而是用卷积一遍完成。
在卷积层上使用滑动窗口算法
- 把网络中的FC层转成1 * 1卷积层。例如:

- 在卷积层上使用滑动窗口

原理:
不需要把输入图像分割成4个子集分别执行前向传播,而是把它们作为一张图像输入给卷积层进行计算。
其中的公有区域可以共享很多计算。
缺点:
边界框的位置可能不够准确。
如何编码bx, by, bw, bh?
每个小格子的坐标都是左上角(0,0)右下角(1,1)。
格子内的坐标都是相对格子左上角(0,0)的。
bx, by的范围是[0, 1],bw, bh有可能大于1。
以上是比较常规的参数形式。YOLO原文有更复杂、效果更好的参数方法。
对象检测算法的评价 - 交并比
IoU — Intersection over Union
= (检测区域 交 真实区域) / (检测区域 并 真实区域)
correct if IoU >= 0.5。
非最大值抑制 Non-max suppression
用于保证每个对象只被检测一次。
例如这种情况,多个格子都检测到了目标。出现这样的结果:
- 把所有p_c <= 0.6的box扔掉。
- 找到剩下的报告中,p_c最高的box,把这个box作为输出。
- 其它box如果与这个box重叠,则按照IoU降低它的p_c。若降至0.5以下,则把box扔掉。
- 如果还有剩下的box, go to 2.
如果检测对象分多个类别,分别对每个类别做非最大值抑制。
Anchor Boxes

如果两个不同对象的中心点落在同一个格子中。怎样才能把两个对象都表示到y中?
(实际上这种case不常见)。
- 预先定义两个不同形状的anchor box

- 对两种对象的检测会生成两个label,每个label都是1*8的向量(根据上文定义)。每个label关联一个anchor box。
- 把两个label合并成一个大的label,大小为1 * 16.

实际上两个对象中心点落在同一个格子的case不常见。
anchor box更多的是另一种作用:针对对象有明显特征的情况可以有针对性地识别。
Anchor Box无法handle以下场景:
- 1个grid中的对象数多于box数
- 1个grid中的多个对象属于相同的box
怎样选择anchor box?
- 手工设计, 5-10个
- K-Means算法对形态进行聚类。
YOLO算法
把以上的技术全部合起来。
训练
标签维度为:19 * 19 * (2 * (1 + 4 + 3))
19: grid数
2:anchor box数
1: pc,用于指示是否存在对象
4:用于指出对象的位置和大小
3:用于指出对象的种类
预测
100 * 100 * 3 –(ConvNet)–> 19 * 19 * 16
用non-max supressed分析输出,每个类别分别作non-max supressed.
候选区域算法
Girshik et. al., 2013. Rich feature hierachies for accurate object detection and semantic
Region Proposals算法又称为R-CNN,不是对整个区域的every single sliding window都作一次检测,而是只是a few windows。
- 使用图像分割算法,分割出色块
- 基于色块运行卷积网络的分类定位算法

缺点:太慢
一些改进:
Fast R-CNN:用卷积实现滑动窗口
Faster R-CNN:使用卷积网络来推荐候选区域

DL Network是怎么学习的
Zeilier and Fergus., 2013. Visiualizing and understanding convolutional networks
分析一个已经训练好的NN:
- 选择layer 1的Unit,观察怎样的输入让这些unit最“兴奋”,得到这样9张图。

- 用同样的方法观察其它layer,每个layer得到这样一些图:




结论:靠后的layer的unit would see a larger region of the image。
网络迁移的算法
Gatvs. et. al., 2015. A newral algorithm of artistic style
这篇论文不难
定义
原图像为Content,简称C
风格图像为Style,简称S
生成图像为Generated,简称G
过程
- 随机初始化G
- 定义代价函数J(G)
- 使用梯度下降法最小化J(G)
$$ G = G - \frac{\partial J(G)}{\partial G} $$
直接更新图像G的像素值。
定义代价函数J(G)
代价函数J(G)由两部分组成:G与C的相似度、G与S的相似度
$$ J(G) = J_C(C, G) + J_S(S, G) $$
$J_C$代价函数
(1)使用某个pre-trained ConvNet,例如VCG
(2)选择网络中的某一层hidden layer来计算content cost,假设使用第l层
- l太小,则生成图像太接近原图像
- l太大,则生成图像与原图像差太多
因此要合理地选择l,通常选择网络的中间层。
(3)定义符号
$a^{l}$和$a^{l}$分别为C和G在第l层的激活值(a,也可写作h)
(4)定义代价函数
认为:如果$a^{l}$和$a^{l}$接近,则图像C和G接近
因此:
$$
J_C(C, G) = \frac{1}{2}||a^{l} - a^{l}||^2
$$
$J_S$代价函数
什么是图像的风格
定义一个图像的style为:correlation between activationas accross channels,即某个Conv层不同channel之间的相关性。
怎样评价两个通道的correlation?
例如这张图,假设图像在某一层上具有这样一些channel。大格子代表不同的channel,小格子代表同一channel关注的不同特征。当某个通道的filter关注某种样式时,另一通道一定关注另一种某个样式,则认为两个通道是high correlation的。相关度correlation表示两个channel同时出现的可能性。
如果一个通道filter关注的样式和另一个通道没有什么关系,则认为是low correlation的。
$J_\text{style}$定义如下:
已知S的每个channel的filter,评价G中how often出现同样的filter组合。
定义符号
$a_{i,j,k}^{[l]}$:图像S中H=i, W=j, C=k的点处的a。
$G^{[l],(S)}$:图像S的第l层的gram matrix/style matrix,大小为$n^{[l]}_c \times n^{[l]}c$
$G^{[l],(S)}{k_1,k_2}$:图像S的第l层通道k1与通道k2的相关性。
gram matrix是线性代数中的术语。
定义代价函数
$$ \begin{aligned} G^{l,s}{k_1k_2} &=& \sum_i\sum_j a{ijk_1}^{ls} * a_{ijk_2}^{ls} \ G^{l,G}{k_1k_2} &=& \sum_i\sum_j a{ijk_1}^{lG} * a_{ijk_2}^{lG} \ J_\text{style}^l(S, G) &=& \frac{1}{2n_H^ln_W^ln_C^l}||G^{ls} - G^{lG}||^2_F \ &=& \frac{1}{(2n_H^ln_W^ln_C^l)}\sum_k\sum_{k’}(G^{l,s}{k_1k_2} - G^{l,G}{k_1k_2}) && \text{分母用于Normalize} \ J_\text{style}(S, G) &=& \sum_l \lambda^l J_\text{style}^l(S, G) \ J(G) &=& \alpha J_\text{content}(C, G) + \beta J_\text{style}(S, G) \end{aligned} $$
$\lambda$是超参数。
内容代价函数只算一层,风格代价函数要遍历所有层。
人脸验证的挑战
(1) One-Shot Challenge:需要通过单一一张图片,就识别到这个人
当DL只有一个样本时,表现非常不好。
(2) 新来一个人时,要改softmax层,因此要重新训练
解决方法:
不直接训练f(图像)=id。
而是训练f(图像1、图像2) = 相似度。
if f(img1, img2) <= t ==> 同一个人
if f(img1, img2) > t ==> 不是同一个人
Taigman et. al., 2014. DeepFace closing the gap to human level performance
网络结构

图像x1 –NN–> 向量v1
图像x2 –NN–> 向量v2
d(图像1,图像2) = $||v_1 - v_2||^2_2$
损失函数
$$ \hat y = \sigma(W(|v_1 - v_2|) + b) $$
$\hat y = 1$ ==> 同一个人
$\hat y = 0$ ==> 不是同一个人
$|v_1 - v_2|$这一部分可以有其它变种。
一种加速计算的trick
训练好的NN可以看作是一个特定的函数f。
可以提前把database中的图像对应的向量都提前算出来,代替原始的样本图像。
把人脸识别转成二分类问题

每张图像生成一个向量,例如xi –> f(xi),xj –> f(xj)
$$
\hat y = \sigma\left(\sum_k w_i d(f(x_i), f(x_j)) + b \right)
$$
其中$d(f(x_i), f(x_j))$代表d(f(x_i), f(x_j))代表f(x_j)和f(x_j)的相似度。
例如X方相关度:
$$
d(f(x_i), f(x_j)) = \frac{(f(x_i)-f(x_j))^2}{f(x_i)+f(x_j)}
$$
在预测时,database中图像的f(x)可以提前准备好(预训练)。
每次只需要重新计算要预测的图像的f(x)即可。
Schroff et. al., 2015. FaceNet: A unified embedding for face recognition and clustering
Triplet Loss
定义三种图像分别为Anchor(A)、Positive(P)、Negative(N)
定义一个三元组的损失函数为:
$$
L(A, P, N) = \max(||f(A) - f(P)||^2 - ||f(A) - f(N)||^2 + \alpha, 0)
$$
其中:
f代表将图像通过神经网络转成向量。
公式原理为:“同一个人的两张图像的距离” 应比 “不同人的两张图像的距离” 小$\alpha$。
$\alpha$为间隔margine。
整个训练集的损失函数为每个三元组的损失之和。
Note:
训练时不是one-shot的,训练集中每个人至少要有2张照片(分别用做A和P),才能完成训练。
在预测时可以是one-shot的。
怎样根据训练集生成三元组?
- 随机生成
缺点:不等式d(A, P) + a <= d(A, N)太容易满足了,NN从中学不到东西。 - 选择“hard to train”的三元组,即d(A, P)和d(A, N)接近的三元组。
优点:加速算法学习
Domain-Adversarial Training
没听懂,截了两幅图

人体姿态估计
人体姿态估计,Human Pose Estimation, HPE
要解决的问题:
- 图像或视频中,人体关节(关键点)的定位问题。
- 所有关节姿势组成的空间中搜索特定姿势。
方法:
- 基于部件组合的传统方法
- 深度学习方法
难点:
- 关节小而灵活
- 衣服遮挡
分类:
- 维度:2D姿势估计、3D姿势估计
- 多人估计的解决思路:top-down(将多人姿势估计转化为单人姿势估计)、bottom-up(先找出图中所有关键点,再对关键点分组)
经典模型
- DeepPose
- 卷积摆位机CPM
- 误差反馈
- 堆叠式沙漏网络Hourglass
- 高分辨率网络HRNet
- CPN, GlobalNet + RefineNet
- Simple Baseslines
- MSPN
- Openpose
- Hourglass + Associative Embedding
- HigherHRNet
损失函数
- 直接对关键点的坐标进行回归
- 为每个关键点预测一个headmap作为关键点的中间表示
数据集
| Name | Training Images | Test Images | Source | Style | Labeled Body Joints |
|---|---|---|---|---|---|
| Frames Labeled In Cinema(FLIC) | 4000 | 1000 | popular Hollywood movies | people in diverse poses and especially diverse clothing | 10 uppep body joints |
| Leeds Sports Dataset(LSD) | 11000 | 1000 | sports activities | quite challenging in terms of appearance and especially articulations | 14 full body joints |
估计指标
-
Percentage of Correct Parts(PCP):正确部件的百分比
如果两个预测的关节位置与真实肢体关节位置之间的距离小于肢体长度的a,则认为肢体被检测到。a通常为0.5。
PCP越大越好。
缺点:由于较短的肢体具有较小的阈值,因此它会对较短的肢体惩罚。 -
Percentage of Detected Joints(PDJ)
-
PCK:正确关键点的百分比
如果预测关节与真实关节之间的距离在特定阈值内,则检测到的关节被认为是正确的。
阈值可以是头骨链接的百分比,或者躯干直径的百分比,或者某个数值。
这个方法不会对较短的肢体有惩罚。
PCK越大越好。
- OKS:对象关键点相似度
参考材料
基本信息
2014 CVPR
地址:https://arxiv.org/abs/1411.4280
将离散热图引入损失函数。
模型
First Stage

多分辨率部分
X:不同的分辨率的full image
单分辨率部分
X:图像的RGB信息
Y:关节的坐标信息
数据预处理:需要先识别出图像中的人,以及把人框住的box。X和Y分别相对于box做normalize。
输入层:完整的图像的normalize,即box
中间层:Alexnet(7层)
输出层:关节在box中的坐标
预期输出:ground truth的normalize
损失函数:输出与预期输出之间的L2 loss

优点:
- 实验证明normalize之后效果更好
- 每个关节都是基于full Image预测的,有holistic reasoning的效果
- 省去了传统方法的大量规则的设计
- 图像中有部分关节没有label的情况也能hold住。
缺点:
- 要求box的识别是可靠的
- 只能做单人识别
- Sequence Stage有做data augment,为什么First Stage不这么做?
- 相对于传统方法,需要大量训练数据
Sequence Stage
X:图像的RGB信息
Y:关节的坐标信息
数据预处理:X和Y分别相对于box做normalize。和First Stage的区别是box的设定。此处的box不再是整个人。box是的中心点要refine的关节在上一个stage中的预测点。box的宽和高根据人的大小来设定。
输入层:完整的图像crop之后的box
中间层:Alexnet(7层),同First Stage
输出层:关节在box中的坐标
预期输出:ground truth基于box的normalize,再增加一定量的noise
损失函数:输出与预期输出之间的L2 loss
优点:
- 每次都基于上一次的subimage做refine,结果会越来越准确
- 对预期输出增加一定量的noise,有data augment的作用,提升泛化能力。
缺点:
- 由于每个关节的box是不同的,一次只能针对一个关节做Refine
- 如果上一个stage预测结果与ground truth偏差比较大,会影响这个stage的准确性
- refine所使用的是原图像的crop,文中没有提到提升sub-image的分辨率,因此信息是变少了。但若有提升分辨率,那么数据量没有少,就没有解决文中所说的“the network has limited capacity to look at detail”的问题了
- 如果box中有别人的关节干扰会怎样?会不会box被跑偏?
- 相对于传统方法,需要大量训练数据
结果与分析
-
Table 1表明Deep Pose整体表现不错。
作者认为表现不错的原因是:Stage 1以整张图像作为输入,可以学到holistic reasoning。代价是更多的训练数据和更长的训练时间,但这个维度的比较在文中没有体现。 -
Figure 3表明在FLIC数据集上,当阈值小的时候,各种方法相差不多。当阈值大时,Deep Pose表现出优势。
-
Figure 4表明在LSP数据集上,当阈值小的时候,Deep Pose略差。当阈值大时,Deep Pose表现出优势。说明Deep Pose精度不够。
-
Figure 5表明Sequence Stage对First Stage的结果有refine作用,且主要的提升在第2个Stage。
作者认为这是因为Stage 2用的是Stage的smaller sub-image,而且其它Stage用的image与前一个Stage大小相同,只是内容有偏移。 -
Fiture 7表明,在不同数据集的泛化能力上,当阈值小的时候,Deep Pose略差。当阈值大时,Deep Pose表现出优势。
实践
本章节包含基于预训练模型的实际应用:
读入 VGG16 预训练模型
模型名: imagenet-vgg-verydeep-19.mat
模型下载地址:
https://www.vlfeat.org/matconvnet/pretrained/
模型介绍: https://windmissing.github.io/DeepLearningNotes/CaseStudy/ClassicNetwork.html
模型结构:
| 维度 | 含义 | 值 |
|---|---|---|
| 0 | ‘layers’ | |
| 1 | 0 | |
| 2 | 层索引 | [0, 42] |
| 3 | 0 | |
| 4 | 0 | |
| 5 | 信息分类 | 0:name 2:参数 |
| 6 | 0 | |
| 7 | 参数 | 第5维是2时,0:W, 1:b。第5维是0时,这里是0 |
W = vgg['layers'][0][layer][0][0][2][0][0]
b = vgg['layers'][0][layer][0][0][2][0][1]
layername = vgg['layers'][0][layer][0][0][0][0]
加载模型
class ModelLoader():
def __init__(self, path):
vgg = scipy.io.loadmat(path)
self.vgg_layers = vgg['layers']
self.layerlist = self._create_layer_list()
tf.keras.backend.set_floatx('float64')
def _weights(self, layer, expected_layer_name):
"""
Return the weights and bias from the VGG model for a given layer.
"""
wb = self.vgg_layers[0][layer][0][0][2]
W = wb[0][0]
b = wb[0][1]
layer_name = self.vgg_layers[0][layer][0][0][0][0]
assert layer_name == expected_layer_name
return W, b
def _conv2d_relu(self, layer, layer_name, input_shape=None):
"""
Return the Conv2D layer using the weights, biases from the VGG
model at 'layer'.
"""
W, b = self._weights(layer, layer_name)
W = tf.cast(tf.constant(W),dtype=tf.float64)
b = tf.cast(tf.constant(np.reshape(b, (b.size))),dtype=tf.float64)
if input_shape:
return tf.keras.layers.Conv2D(filters=(W.shape[3]), kernel_size=(W.shape[0], W.shape[1]),
padding='SAME', kernel_initializer=ExampleRandomNormal(W),
bias_initializer=ExampleRandomNormal(b), activation='relu',
input_shape=input_shape)
else:
return tf.keras.layers.Conv2D(filters=(W.shape[3]), kernel_size=(W.shape[0], W.shape[1]),
padding='SAME', kernel_initializer=ExampleRandomNormal(W),
bias_initializer=ExampleRandomNormal(b),activation='relu')
def _avgpool(self):
"""
Return the AveragePooling layer.
"""
return tf.keras.layers.AveragePooling2D(padding='same')
def _create_layer_list(self):
return [self._conv2d_relu(0, 'conv1_1', input_shape=(CONFIG.IMAGE_HEIGHT, CONFIG.IMAGE_WIDTH, CONFIG.COLOR_CHANNELS)),
self._conv2d_relu(2, 'conv1_2'),
self._avgpool(),
self._conv2d_relu(5, 'conv2_1'),
self._conv2d_relu(7, 'conv2_2'),
self._avgpool(),
self._conv2d_relu(10, 'conv3_1'),
self._conv2d_relu(12, 'conv3_2'),
self._conv2d_relu(14, 'conv3_3'),
self._conv2d_relu(16, 'conv3_4'),
self._avgpool(),
self._conv2d_relu(19, 'conv4_1'),
self._conv2d_relu(21, 'conv4_2'),
self._conv2d_relu(23, 'conv4_3'),
self._conv2d_relu(25, 'conv4_4'),
self._avgpool(),
self._conv2d_relu(28, 'conv5_1'),
self._conv2d_relu(30, 'conv5_2'),
self._conv2d_relu(32, 'conv5_3'),
self._conv2d_relu(34, 'conv5_4'),
self._avgpool()]
def _create_model_with_part_layer(self, num=-1):
model = tf.keras.Sequential(self.layerlist[:num])
return model
def test_get_model_weight():
# W, b = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")._weights(0, 'conv1_1')
vgg = scipy.io.loadmat("../pretrained-model/imagenet-vgg-verydeep-19.mat")
assert 'layers' in vgg.keys()
assert len(vgg['layers']) == 1
assert len(vgg['layers'][0]) == 43
layer = 0
name = 'conv1_1'
type = 'conv'
assert len(vgg['layers'][0][layer]) == 1
assert len(vgg['layers'][0][layer][0]) == 1
assert len(vgg['layers'][0][layer][0][0]) == 9
assert vgg['layers'][0][layer][0][0][0][0] == name
assert vgg['layers'][0][layer][0][0][1][0] == type
W = vgg['layers'][0][layer][0][0][3][0]
assert len(vgg['layers'][0][layer][0][0][2]) == 1
assert len(vgg['layers'][0][layer][0][0][2][0]) == 2
assert (vgg['layers'][0][layer][0][0][2][0][0]).shape == tuple(W) # weights of filter
assert (vgg['layers'][0][layer][0][0][2][0][1]).shape == (W[3], 1) # bias
assert len(vgg['layers'][0][layer][0][0][4][0]) == 4 # stride
def test_model_loader_weight():
loader = ModelLoader("../pretrained-model/imagenet-vgg-verydeep-19.mat")
W, b = loader._weights(0, "conv1_1")
assert W.shape == (3,3,3,64)
assert b.shape == (64, 1)
def test_model_loader_layer():
loader = ModelLoader("../pretrained-model/imagenet-vgg-verydeep-19.mat")
layer = loader._conv2d_relu(0, "conv1_1")
def test_model_loader_create_layers():
loader = ModelLoader("../pretrained-model/imagenet-vgg-verydeep-19.mat")
layerlist = loader._create_layer_list()
assert len(layerlist) == 21
def test_create_model_with_part_layer():
loader = ModelLoader("../pretrained-model/imagenet-vgg-verydeep-19.mat")
model = loader._create_model_with_part_layer(5)
if __name__ == '__main__':
print ("model loader test begin")
test_get_model_weight()
test_model_loader_weight()
test_model_loader_layer()
test_model_loader_create_layers()
test_create_model_with_part_layer()
print ("model loader test passed")
基于预训练模型的图像重构
-
加载预预训练模型,以VGG19为例,见上一页。
-
生成一张白噪声图像
-
定义原图像为a,生成的图像为g,它们经过预训练模型后,第l层的输出为F(a, l)和F(g, l)。
-
定义损失函数为:
$L = |F(a, l) - F(g, l)|_2$把模型参数作为常量,把图像像素作为变量,进行梯度下降的迭代
- 最后得到的g为基于预训练模型第l层得到的重构图像
结论:
l层越低(靠近输入层),还原度越高,画面越精细。
from utils import load_vgg_model
import imageio
import tensorflow as tf
CONTENT_IMAGE = "images/content_wind_400300.jpg"
INIT_GENERATE = CONTENT_IMAGE
CONTENT_LAYER = 4
def calculate_a_C(model, layer_id):
content_image = imageio.imread(CONTENT_IMAGE)
content_image = load_vgg_model.reshape_and_normalize_image(content_image)
a_C = model(content_image)
return a_C
def read_init_generate(content = "copy"):
if content == "copy":
generated_image = imageio.imread(INIT_GENERATE)
generated_image = load_vgg_model.reshape_and_normalize_image(generated_image)
else:
image = imageio.imread(INIT_GENERATE)
generated_image = load_vgg_model.generate_noise_image(image)
generated_image = tf.Variable(initial_value=generated_image, dtype=tf.float64)
return generated_image
def processing(input_image):
a_G = content_model(input_image)
# Compute the content cost
J = compute_content_cost(a_C, a_G)
print ("cost = ", J)
return J
def compute_content_cost(a_C, a_G):
"""
Computes the content cost
Arguments:
a_C -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing content of the image C
a_G -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing content of the image G
Returns:
J_content -- scalar that you compute using equation 1 above.
"""
### START CODE HERE ###
m, n_H, n_W, n_C = tf.shape(a_G)
# Reshape a_C and a_G (≈2 lines)
a_C_unrolled = tf.reshape(a_C, shape=[m, n_H * n_W, n_C])
a_G_unrolled = tf.reshape(a_G, shape=[m, n_H * n_W, n_C])
# compute the cost with tensorflow (≈1 line)
J_content = (tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled, a_G_unrolled)))) / tf.cast((4 * n_H * n_W * n_C), tf.float32)
### END CODE HERE ###
return J_content
def model_nn(input_image, num_iterations=200):
for i in range(num_iterations):
print ('interation: %d', i)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(input_image)
J = processing(input_image)
# save last generated image
gradients = tape.gradient(J, input_image)
optimizer = tf.keras.optimizers.Adam(2.0)
optimizer.apply_gradients([(gradients, input_image)])
# load_vgg_model.save_image('output/generated_image_' + str(i) + '.jpg', input_image)
load_vgg_model.save_image('output/generated_image_' + str(i) + '.jpg', input_image)
return generated_image
tf.enable_eager_execution()
loader = load_vgg_model.ModelLoader("pretrained-model/imagenet-vgg-verydeep-19.mat")
content_model = loader._create_model_with_part_layer(CONTENT_LAYER)
a_C = calculate_a_C(content_model, layer_id=-1) # 'conv4_2' #浣犳兂瑕佽幏寰楄緭鍑虹殑鍘熷妯″瀷涓偅涓€灞傜殑鍚嶇О
generated_image = read_init_generate(content="noise")
model_nn(generated_image)
基于预训练模型的风格重构
风格重构又称为纹理提取,过程与内容重构类似,区别只是损失函数的计算方法不同。
-
加载预预训练模型,以VGG19为例,见上一页。
-
生成一张白噪声图像
-
定义原图像为a,生成的图像为g,它们经过预训练模型后,第l层的输出为F(a, l)和F(g, l)。
-
定义任意图像p的风格为gram矩阵
$G^l_{ij} = \text{correlation}(p^l_i, p^l_j)$
- 定义损失函数
$L = |G(a, l) - G(g, l)|_2$把模型参数作为常量,把图像像素作为变量,进行梯度下降的迭代
- 最后得到的g为基于预训练模型第l层得到的重构图像
结论:
l层越高(靠近输出层),像素越连续。
import tensorflow as tf
# GRADED FUNCTION: gram_matrix
def gram_matrix(A):
"""
Argument:
A -- matrix of shape (n_C, n_H*n_W)
Returns:
GA -- Gram matrix of A, of shape (n_C, n_C)
"""
### START CODE HERE ### (鈮? line)
GA = tf.matmul(A, tf.transpose(A))
### END CODE HERE ###
return GA
# GRADED FUNCTION: compute_layer_style_cost
def compute_layer_style_cost(a_S, a_G):
"""
Arguments:
a_S -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing style of the image S
a_G -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing style of the image G
Returns:
J_style_layer -- tensor representing a scalar value, style cost defined above by equation (2)
"""
### START CODE HERE ###
# Retrieve dimensions from a_G (鈮? line)
# m, n_H, n_W, n_C = a_G.get_shape().as_list()
m, n_H, n_W, n_C = tf.shape(a_G)
# Reshape the images to have them of shape (n_C, n_H*n_W) (鈮? lines)
a_S = tf.transpose(tf.reshape(a_S, shape=[n_H * n_W, n_C]))
a_G = tf.transpose(tf.reshape(a_G, shape=[n_H * n_W, n_C]))
# Computing gram_matrices for both images S and G (鈮? lines)
GS = gram_matrix(a_S)
GG = gram_matrix(a_G)
# Computing the loss (鈮? line)
J_style_layer = (tf.reduce_sum(tf.square(tf.subtract(GS, GG)))) / (tf.cast((4 * n_H * n_W * n_C), tf.float64) ** 2)
### END CODE HERE ###
return J_style_layer
def compute_style_cost(modellist, STYLE_LAYERS, a_S_Set, generated_image):
"""
Computes the overall style cost from several chosen layers
Arguments:
model -- our tensorflow model
STYLE_LAYERS -- A python list containing:
- the names of the layers we would like to extract style from
- a coefficient for each of them
Returns:
J_style -- tensor representing a scalar value, style cost defined above by equation (2)
"""
# initialize the overall style cost
J_style = 0
for layer_name, coeff, layer_id in STYLE_LAYERS:
a_G = modellist[layer_name](generated_image)
a_S = a_S_Set[layer_name]
J_style_layer = compute_layer_style_cost(a_S, a_G)
J_style += coeff * J_style_layer
return J_style
def test_gram_matrix():
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as test:
tf.compat.v1.set_random_seed(1)
A = tf.compat.v1.random_normal([3, 2 * 1], mean=1, stddev=4)
GA = gram_matrix(A)
print("GA = \n" + str(GA.eval()))
def test_compute_layer_style_cost():
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as test:
tf.compat.v1.set_random_seed(1)
a_S = tf.compat.v1.random_normal([1, 4, 4, 3], mean=1, stddev=4)
a_G = tf.compat.v1.random_normal([1, 4, 4, 3], mean=1, stddev=4)
J_style_layer = compute_layer_style_cost(a_S, a_G)
print("J_style_layer = " + str(J_style_layer.eval()))
# J_style_layer = 9.190278
什么是语言模型
S1 = “The apple and pair salad”
S2 = “The apple and pear salad”
S1和S2语音相近,为什么选择S2而不是S1?
因为语言模型。在语言模型中,P(S2) > P(S1),因此选择S2。
语言模型用于评估一个句子发生的可能性。
怎样构建语言模型
训练集:大量的语料库corpus
tokenize
即把单词序列转成token序列,token是one-hot向量。
除了每个字符有对应的token以外,增加两个token:
<EOS>:表示序列结束的字符<unk>:表示字符不在字典中
标点不用转成token
定义模型结构

定义损失函数
$$ \begin{aligned} L(\hat y^t, y^t) &=& -\sum_i(y_i^t\log\hat y_i^t) \ L &=& \sum_t L(\hat y_t, y_t) \end{aligned} $$
图像中第t个unit用于计算给出t-1个单词的情况下,第t个单词是某个单词的概率。
把前t个unit的结果相乘表示t个单词组成一句话的概率。
新序列采样
目的:训练了一个语言模型之后,想了解模型学到了什么
softmax采样
由softmat生成每个单词的概率分布。
用np.random.choice基于概率分布进行采样。
这里和训练的主要区别是:使用$\hat y$还是y作为下一个t的输入。
字符级别的RNN
上面都是单词级别的RNN。
也可以训练一个字符级别的RNN。
优点:不用担心出现未知的token
缺点:
生成的序列比较长。序列太长,前面对后面的影响就会小。
训练成本高。
词汇表征
词汇表征是自然语言处理中的基础任务,旨在将单词转换为计算机可处理的向量表示。
本章包含以下内容:
- One-hot Embedding
- Word Embedding
- 类比推理
- 用语言模型学习 Embedding Matrix
- Word2Vec 算法
- skip-grams 算法
- 负采样算法
- 词向量算法
- 词嵌入除偏
- Embedding
One-Hot表示法
例如单词表为:lexicon = {apple, ball, cat}
那么这三个单词的向量依次为:
apple = [1 0 0 0]
ball = [0 1 0 0]
cat = [0 0 1 0]
其它单词 = [0 0 0 1]
缺点:
把每个词孤立起来(任意两个向量的内积为0),这使得模型对词的泛化能力不强。
例如,从“I want a glass of orange juice”泛化到“I want a glass of apple juice.”
word hashing:

缺点
it treats each word as a thing only to itself.
例如:
I want a glass of orange ______.
I want a glass of apple ______.
对于以上两种表征方式,orange和apple没有内在的联系,和其它单词是一样的,因此无法将第一句的知识泛化到第二句。
特征化表示: word embedding
Word Embedding是基于特征的representation。
这只是一个人为构造的例子。实际上这个矩阵中每一行的含义以及矩阵中的数值都是DL学习出来的,每个维度的含义不一定能被 人理解。
可视化embedding
van der Maaten and Hinton., 2008. Visualizing data using t-SNE
使用t-SNE把n维的embedding转换到二维的空间。
word embedding的优点
- word embedding通过非常大量的语料库(1-100B)生成。
使用者可以预先训练好或者直接下载开源的word embedding,然后把它迁移到自己的模型中并微调。 - 即使自己的模型只有很小的训练集(100K),也能有比较好的效果。
- embedding向量比one-hot向量小。
word embedding广泛应用于NLP问题中,这是一种迁移学习。
Word Embedding VS Face Encoding
word embedding和face encoding的原理类似,区别是使用时:
face encoding输入的可能是没有见过的图像。
word embedding输入的是字典中的单词。
Embedding Matrix
假设单词表的大小为10000,embedding后每个单词的维度是300,则Embedding矩阵E的维度是300 * 10000
例如单词ID是6527,它的One-hot Embedding记为$O_{6527}$,维度是10000 * 1,它的Word Embedding记为$e_{6527}$,维度是300 * 1,则:
$$ e_{6527} = E \cdot O_{6527} $$
实际上不会使用这种矩阵乘法来计算Word Embedding,而是使用专用的列查找算法。
Mikolov et. al., 2013. Linguistic regualrities in continuous space word representations
类比推理
man -> woman, king -> ?
向量相减
$$ e_{\text{man}} - e_{\text{woman}} \approx e_{\text{king}} - e_{w} $$
找到一个w使式子成立:
$$
w = \arg\max_w \text{sim}(e_{w}, e_{\text{king}} - e_{\text{man}} + e_{\text{woman}})
$$
公式中的sim代表相似度计算公式,有“余弦相似度”和“平方相似度”。余弦相似度更常用。
- 余弦相似度:
$$ \text{sim}(u, v) = \frac{u^\top v}{||u||_2||v||_2} $$
公式中的$u^\top v$计算u、v夹角的余弦值,因此称为余弦相似度。
- 平方相似度:
$$ \text{sim}(u, v) = - ||u-v||^2 $$
用语言模型学习Embedding Matrix
Bengio et. al., 2003. A neura; probabilistic language model
I want a glass of orange ______.
语言模型的目标是预测下一个单词。
- 提取target的前K个单词。
- one shot向量经过embedding matrix得到embedding向量
- embedding向量通过RNN神经网络进行训练
- softmax作为NN的输出Unit,来计算w是每个单词的概率。

这个模型中有softmax的参数和E的参数,都可以通过GD迭代得到。
Word2Vec 算法
Mikolov et. al., 2013. Efficient estimation of word representations in vector space
构造监督学习问题
学习Word Embedding本是一个非监督学习的问题,可以先把它转换成等价的监督学习问题,然后GD迭代求出模型的参数。
通过抽取上下文context和目标target词配对,来构造监督学习问题。
定义:
One-hot Vector: Oc
Embedding Matrix: E
Embedding Vector: Ec
有:
Ec = E * Oc
Word2Vec与NLP语言模型主要区别在于选取context和target的方式不同。
Word2Vec选择context前后的k范围内的词作为target,与context构造一对。
context是特征,target是标签。
一个特征对应多标签,这样构造出来的监督问题不是为了预测标签,而是为了学习Embedding。
模型结构
Word2Vec与NLP语言模型使用的网络结构类似 ,通过NN建立context到target的映射。
由softmax生成的概率模型为:
$$
p(t|c) = \frac{\exp{\theta^\top_t e_c}}{\sum_t \exp{\theta^\top_t e_c}}
$$
公式中$\theta^\top_t$是与输出t有关的参数。
定义损失函数为:
$$
L(\hat y, y) = -\sum y_i \log \hat y_i
$$
通过迭代可以学到E的参数和softmax的参数。softmax参数就是$\theta_t$,E的参数就是embedding matrix。
Skip-Gram Model
Skip-grams与Word2Vec算法相似,只是选择context和target的方法不同。
skip-context的目标是:给一个context,输出从context skip一些单词之后的单词。
基于NLP语言模型的改进。
在NLP语言模型中,使用target的前K个单词作为context.
如果目标不是生成语言模型,而是用于训练类比推理,可以使用其它类型的context.
遗留问题
问题1: 公式p(t|c)的分母计算非常慢
$$ p(t|c) = \frac{\exp{\theta^\top_t e_c}}{\sum_t \exp{\theta^\top_t e_c}} $$
解决方法:分组的softmax
问题2:怎么采样生成context?
- 均匀随机采样: the, of, a等词频繁出现和更新,orange, apple, durian较少出现和更新
- 启发算法:用于平衡常见词和不常见词
Mikolov et. al., 2013. Distributed representation of words and phrases and their compositionality
负采样 negative sample,可以解决Word2Vec和skip-grams中p(t|c)计算太慢的问题。
算法过程
- 从句中选择一个context
- 从context的范围内生成一对word(同Word2Vec),(context, word)构成一个正样本,定义其label为1
- 从单词表中随机选择一个word,(context, word)构成一个负样本,定义这k个负样本的label为0。
- 重复第3步k次,得到k个负样本。
- 用正/负样本对及其对应的label训练模型(监督学习)
$$ P(y=1|c, t) = \sigma(\theta^\top_t e_c) $$
优点
相当于把大小为1000个类别的多分类问题转换成1000个二分类问题。
但并不是每次都把1000个二分类问题都算了,而是只更新k+1个二分类的结果。
遗留问题
问题1:如何决定k?
for larger corpus, [5, 20]
for smaller corpus, [2, 5]
数据集大则k小,数据集小则k大。
问题2:如何选择负样本的context?
- 根据词出现的频率进行采样:the, of, and…问题
- 均匀随机抽取:样本没有代表性
- 启发算法
$$ P(w_i) = \frac{f(w_i)^{\frac{3}{4}}}{\sum f(w_i)^{\frac{3}{4}}} $$
公式中$f(w_i)$代表词频。
词向量算法
Pennington et. al., 2014. Glove: Global vectors for word representation
GloVe = Global Vector = 词向量
特点:简便
-
定义:
$X_{ij}$为target i出现在context c中的次数
遍历corpus统计$X_{ij}$。
$X_{ij}$是否对称与如何定义context有关。 -
优化
$$ \sum_i\sum_j f(X_{ij})(\theta^\top_i e_j + b_i + b_j’ - \log X_{ij})^2 $$
关于$f(X_{ij})$
- 公式中$f(X_{ij})$为权重:
- 当$X_{ij} = 0$时,$f(X_{ij})$必须定义为0。否则上面这个公式没有意义。
- $X_{ij}$可能差别很大,$f(X_{ij})$应保留$X_{ij}$的大小关系(单调),但不能让它们的差别过于悬殊。
关于$e$和$\theta$:
$e$和$\theta$是对称的,因此将$e$和$\theta$初始化为相同的值,迭代之后:
$$
e_w^{final} = \frac{e_w + \theta_w}{2}
$$
这是因为在这个算法里,$e$和$\theta$的意义是相同的,而之前的算法中$e$和$\theta$不同。
词嵌入除偏 Debiasing
Bolukbasi et. al., 2016 Man is to computer programmer as woman is to homemaker?
word embedding中的bias反映了corpus中的bias。
用于消除种族歧视、性别歧视等。
例如:
Man:Woman -> King:Queen
Man:程序员 -> Woman:家庭主妇
- 识别bias的方向,以及中轴

- 中和步 neutralization step
有明确的性别分别的词,例如:boy, girl, he, she
没有性别区分的词,例如doctor, nurse, programmer, homemaker
将第二类词中和,即消除它们到中轴的距离。
- 平衡步 equalize
目标:使第一类词对到中轴的距离相等
问题:怎样判断一个词是第一类词还是第二类词?
答:训练一个NN来判断。
目标:通过word的context来理解word的关系。
难点:怎样挖掘word的context?
Count based算法
原理:Wi和Wj经常co-occor,则V(Wi)和V(Wj)接近。
Glove Vector
Ag也有讲这个算法link
Predition Based算法
基本算法
- 训练一个NN,输入$w_{i-1}$,预测$w_i$是每个单词的概率。

- 把NN中的第1个hidden layer拿出来,即z
- 用z代表单词wi
原文中NN部分只有1个hidden layer。因此1个hidden layer的计算量,因此可以跑大量的Data。
算法拓展
基于$w_{i-1}$ 拓展为 基于wi的几N个单词,
同时结合参数共享的思想。
参数共享的原理:同一个单词放在wi之前的不同位置,效果应该相同。
算法变形
(1)基于wi前后的单词预测wi
(2)基于wi预测wi前后的单词
Embedding算法的应用
Word Embedding
- 相同关系的两个词的向量的相对位置类似

图中左边为国家与首都的向量关系,右边为动词三次的向量关系。 - 相同关系的两个词的向量相减,结果落在同一区域。

多语言 Embedding

- 对两种语言分别做embedding,此时两种embedding没有任何关系。
- 基于一些确定的中英词对,将两种embedding映射到同一空间。图如图中绿底中文和绿框英文。
- 此时出现新的中文embedding与英文embedding,经过相同的映射后,会出现在附近的位置。例如图中绿底中文和黄底英文。
多领域 Embedding
- 同一类别的图像出现在Embedding空间的同一位置
- 一张新图,通过Embedding向量周边向量的类别来确定这张新图的类别。
参考上文提到的Zero-Shot问题。
文件Embedding
不同长度的文件 –> 相同长度的vector
静态Embedding法
缺点:Bag of word没有考虑到内容中单词的顺序
改进:没讲
领域 Neighbor Embedding
Manifold Learning,相当于非线性的降维
经典例子:地球表面
引入原因:由于低维空间的点在高维空间扭曲,导致原本的“距离”可能没有意义。
解决方法:把点在低维空间拉平
方法一:LLE
-
任意选择一个点xi
-
任意选择点xi的Neighbour,即点xj
-
定义xi与xj的关系为$W_{i,j}$
-
最小化以下公式:
$$ \sum_i||x^i - \sum_j W_{i,j}x^j||_2 $$ -
降维,把xi, xj转成zi,zj,降维后$W_{i,j}$不变。
$$ \sum_i||z^i - \sum_j W_{i,j}z^j||_2 $$
优点:
不需要知道原xi, xj,只要知道$W_{i,j}$,就可以求出降维后的zi, zj。
方法二:Laplacian Eigenmaps
两个点的距离不是欧氏距离,而是两个点间的high density path

$$ S = \frac{1}{2}\sum_{i,j}W_{i,j}(z^i - z^j)^2 $$
$\sum_{i,j}$代表遍历所有的数据对,但只有$W_{i,j}$大的情况下,才会考虑对(z^i - z^j)^2影响。
$W_{i,j}$大的情况下,(x^i - x^j)^2肯定小,按照以上公式,这种情况$(z^i - z^j)^2$也必须小。
另外,为了防止训练结果为所有的z都为0,还需要再加一个要求:
$$
Span(z1, z2, \cdots, zm) = R^m
$$
方法三:t-SNE
T-distributed Stochastic Neighbour Embedding
https://blog.csdn.net/scott198510/article/details/76099700
方法一、二存在的问题:
只要求相似的点靠近,没有要求不同的点分开,所以最后所有的点都挤到一起。
T-SNE可以解决这样的问题。
训练步骤:
-
计算所有点对的相似度: S(xi, xj),两个点之间距离越近,相似度越大。
-
Normalization
$$ P(x^j|x^i) = \frac{S(x^i, x^j)}{\sum_{k\neq i}S(x^i, x^k)} $$ -
在低维空间随机生成同样多的点z,假设zi, zj就是xi, xj对应的转换结果,计算S’(zi, zj)
-
Normalization
$$ Q(z^j|z^i) = \frac{S’(z^i, z^j)}{\sum_{k\neq i}S(z^i, z^k)} $$
假设上图中左图为高维空间的点x1计算出来的归一化之后的相似度。右图是低维空间点z1计算出来的归一化之后的相似度。
每一组相似度都可以看作是一个Multinomial分布。 -
计算分布P与分布Q的相似度,使用的指示是KL divergence(KL散度)
对每个点“在高维空间的相似度分布P”和“低维空间的相似度分布Q”之间的相似度(KL散度)。
所有点计算出的KL散度之和就是这个模型的Loss Function。
$$ \begin{aligned} L &=& \sum_i KL\left(P(|x^i)||Q(|z^i)\right) \ &=& \sum_i \sum_j P(x^j|x^i)\log \frac{P(x^j|x^i)}{Q(x^j|x^i)} \end{aligned} $$ -
通过不断迭代调整z的位置降低Loss。
缺点:
(1)计算量大
解决方法:先使用PCA降维,例如:50维 –PCA–> 10维 –t-SNE–> 2维
(2)如果来一个新的x,要求x对应的z,需要把算法重新跑一遍。
解决方法:该算法不用于训练模型,而是主要用于数据的可视化
t-SNE的一个关键的创新点:
x的相似度计算公式S和z的相似度计算公式S’不同。
$$
\begin{aligned}
S(x^i, x^j) = \exp(-||x^i-x^j||_2) \
S’(z^i, z^j) = 1/1 + ||z^i-z^j||_2
\end{aligned}
$$
S与S’的关系如图所示:
图中蓝线是高维空间数据的S公式。绿线为低维空间数据的S’公式。
当xi与xj接近时,zi与zj之间的距离更近。
当xi与xj比较远时,zi与zj的间隔更远(强化gap)。
效果:
情绪分类的主要挑战: 没有那么多有标记的训练集
解决方法: Word Embedding
简单的情绪分类

- 把one shot向量转成word embedding向量
- 句子中的所有向量做Average操作。
- 基于softmax生成分类结果
优点:适用于任意长度的文本
缺点:缺少词序,例如:
Completely lacking in good taste, good service and good ambience.
这句很可能会误分类。
RNN的Many to One结构

NMT
layout: post title: “NLP NMT综述” category: [Machine Learning] tags: []
NMT = neural machine translation
分类
- 多语言/领域NMT & 单语言/领域NMT
- 自回归NMT/非自回归NMT
- word/character level NMT
- 实时翻译/全句翻译
单语言NMT
经典模型是transformer: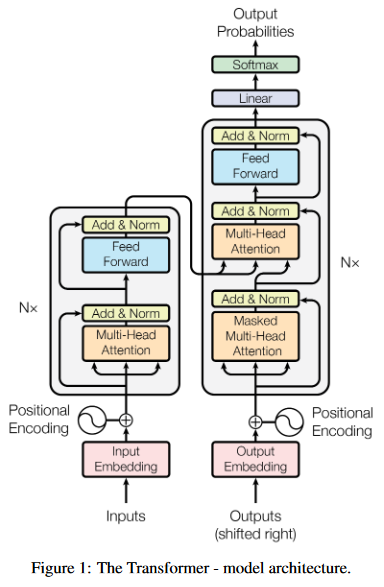
特点是:
- 每个NX代表一个完整的一层
- Encoder每层有2个sublayer,分别是ATT和FNN
- Decoder每层比Encoder多一层masked-ATT
- 每个sublayer之后都有Add&Norm
- Sublayer之间是残差网络
transformer的改进:
- 新的attention function,使用scaled dot-product作为alignment score。
- a multi-head attention modlule,使得NMT模型可以jointly attend to information from different representations at different positions。
多语言NMT
多语言NMT是指在一个模型中完成多对语言之间的翻译,具体可以分为一对多、多对一、多对多。
多语言NMT要解决的问题有:
- 单个语言的翻译性能不如单语言模型
- zero-shot问题。多语言NMT使得zero-shot翻译成为可能,但它的zero-shot翻译质量并不好。
提升语言翻译性能的方法
- 每个语言都有对应的encoder/decoder
例如:
一对多翻译,共享encoder
多对多翻译,多个语言共享attention mechanism
缺点:scalability受到限制。
- 把不同语言映射到同一个表示空间
例如:
with a target language symbol guiding the translation direction
缺点:
忽略了不同语言的linguistic diversity
- 在2的基础上,加入“语言的linguistic diversity”的考虑
例如:
reorganizing parameter sharing
designing language-specific parameter generator
decoupling multilingual word encoding
解决zero-shot问题的方法
多语言NMT处理zero-shot数据时(相对于pivot-based模型)会出现“off-target translation问题”,即翻译成一个错误的语言。
出现问题的原因:
- missing ingredient problem
- spurious correlation issue
解决方法:
- 跨语言正则化
- generating artificial parallel data with backtranslation
字符级NMT
Encoder:CNN层 + max pooling层 + highway层 + attention
Decoder:每次生成一个Character
在多语言场景中,字符级NMT非常有用,表现在:
- 两种语言有几乎相同的字符表,例如French和Spanish
- 两个差别较大的语言映射到一个共同的字符表,例如latinzing Russian和Chinese
transformor + 字符级 效果也不错。
自回归模型
target sentence的每个output token都与之前的output token有关,因此token是一个一个产生的。
生成长度为n的output需要经过n次迭代。
非自回归模型(NAT)
NAT,Non-Autogressive Machine Translation
不考虑sequential condition dependency,并行生成输出
时间复杂度:O(n) -> O(k)
优点:速度大幅提升
缺点:性能下降
原理:knowledge distillation,用于sequence-level distilled outputs
主要研究方向:缩小NAT与AT之间的性能差距
一些提升NAT性能的方法:
- takes a copy of the encoder input x as the decoder input, and trains a fertility predictor to guide the copy procedure
- generate the target sentence by interatively refining the current translation
- extra loss function
- change the generation order:左->右 ==》 tree-based
- multi-iteration refinements
- rescoring with 自回归模型
- aligned cross entropy/latent alignment mode(SOTA)
Masked 语言模型(BERT)
把输入序列的subset tokens用MASK代替,通过residual tokens推断missing tokens
[?] Maksed LM与transformer encoder是什么关系?
Energy-based model:
训练一个actor网络来控制AT的hidden state
[?] 这个模型没看懂,ACL.2020.251
实时翻译
基本模型:prefix-to-prefix framework
基于部分源句做预测
policy: wait k policy
音频预处理
通常使用librosa做音频的预处理。
(1) 读入音频文件
sig, rate = librosa.load(path, sr=32000, offset=None)
path: 文件路径
sr:采样率
sig:此时的数据为一维的序列。
(2)用FFT变换,将序列转换为声谱图
# Compute the spectrogram and apply the mel scale
mel_spec = librosa.feature.melspectrogram(y=y,
sr=32000,
n_fft=1024,
hop_length=HOP_LENGTH,
n_mels=NUM_MELS,
fmin=FMIN,
fmax=FMAX)
mel_spec:二维声谱图像
输出长度= (秒)*(采样率)/(hop_length)
输出高度= n_mels
(3)归一化:
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
或
mel_spec_db -= mel_spec_db.min()
mel_spec_db /= mel_spec_db.max()
(4)升维
mel_spec_db = mel_spec_db[np.newaxis,:,:,np.newaxis]
转换为二维单通道的图像,用图像方式来处理
def get_segment_spec(path, second):
sig, rate = librosa.load(path, sr=32000, offset=None)
s_start = (second - 5) * 32000
s_end = second * 32000
y = sig[s_start:s_end]
if y.shape[0] < 1:
return None
# Compute the spectrogram and apply the mel scale
mel_spec = librosa.feature.melspectrogram(y=y,
sr=32000,
n_fft=1024,
hop_length=HOP_LENGTH,
n_mels=NUM_MELS,
fmin=FMIN,
fmax=FMAX)
mel_spec_db = np.array(mel_spec_db)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
#mel_spec_db -= mel_spec_db.min()
#mel_spec_db /= mel_spec_db.max()
mel_spec_db = mel_spec_db[np.newaxis,:,:,np.newaxis]
# print ("mel_spec_db.shape", mel_spec_db.shape)
return mel_spec_db
预处理
音频数据的常见预处理步骤:
- 生成声谱图
- 伪空白输出
音位 phonemes
音位是语言学家定义的发音的基本单位。
在以前语音识别模型中:
音频片段 –> 音位 –> transcript
在现在的语音识别模型(end-to-end)中:
音频片段 –> transcript
注意力模型做语音识别

CTC cost做语音识别
CTC = Connectionist Temporal Classification
basic rule: 将空白符之间的重复字符折叠起来。
用于计算语音识别的cost
[Graves et. al., 2006 Connectionist Temporal Classification: Labelling unsegmented sequence data with recurrent neural networks]
- 输入音频“the quick fox”
- 构造一个双向LSTM/GRU,Tx=Ty且非常大
- 生成的输出可能是这样的:
ttt_h_eee___ ___qqq__
其中_代表空白, 代表空格
- 将空白
_之间的重叠字符折叠起来
触发字检测
触发字 = trigger word = 唤醒词

当检测到唤醒词时输出1,其它时间输出0
缺点:构建了一个很不平衡的训练集
解决方法:
当检测到唤醒词时多输出几个1.
Zero Shot问题是指:
有一组大量labelled data,定义为$(x^s, y^s)$
有一组少量unlabelled data,定义为$(x^t)$
通过$(x^s, y^s)$和$(x^t)$来预测$(y^t)$,但$(x^t)$没有出现在$(x^s)$中。
方法一:以另一种方式分class
在语音识别任务中,每个单词可以看作是一个class。有可能要识别的单词没有出现在训练集中。
解决方法:以单词为class -> 以音位phonemes为class
phonemes是可以穷举的。
- 通过NN把语音转成phonemes。
- 通过预先定义好的table,把phonemes转成单词。
在语音识别任务中,训练集是猫、狗,测试集出现草泥马:
解决方法:以名字作为class -> 以特征作为class
- 分析图像中的动物的特征,例如毛、腿、尾等。
- 通过预先定义好的table,根据特征推测动物的名字。
方法二:attribute embedding

f()将图像转成向量。
g()将特征转成向量。
f和g都通过NN训练得到,训练的目标是$f(x^n)$和$g(y^n)$越接近越好。
也可以用动物的名字代替特征(attribute embedding + word embedding):
定义loss function如下:
$$
\begin{aligned}
L = \sum_n max\left(0, k-f(x^n)g(y^n) + max_{m\neq n}f(x^n)g(y^n) \right) && (1)\
f*, g* = \arg\min_{f,g} L && (2)
\end{aligned}
$$
目标是要最小化L。当max{}的第二项小0时,L取到最小值0。即:
$$
\begin{aligned}
f(x^n)g(y^n) - max_{m\neq n}f(x^n)g(y^n) > k && (3)
\end{aligned}
$$
公式(3)左边第一项代表:$f(x^n)$和$g(y^n)$应尽量接近
公式(3)左边第二项代表:$f(x^n)$和$g(y^m)$应尽量远离
方法三:Convex Combination of Sematic Embedding
假设有一张图像,NN的分类结果为:P(lion) = 0.5, P(tiger) = 0.5
- 找到向量$V_{tiger}$和$V_{lion}$
- 计算向量$v = P(lion)V_{lion} + P(tiger)V_{tiger}$
- 找到离v最近的标签,因此得到liger
- 图像分类为liger

background
用PCA的降维-升维的过程来类比auto-encoder的编码-解码过程。
PCA降维:高维特征的图像 * $W$ = 低维特征的图像
PCA升维:低特征的图像 * $W^\top$ = 高维特征的图像
auto-encoder的编码:高维特征图像 经过encoder –> 向量c
auto-encoder的解码:向量c 经过decoder –> 高维特征图像
把编码和解码通常放在一起训练,中间的向量c可以看作是一个hidden layer的activation。c又称为bottleneck.
deep NN版的auto-encoder

auto-encoder中的编码器和解码器都是deep NN,那么就称为深度自编码器(deep auto-encoder)。
deep auto-encoder编码器的应用
用于图像压缩与解压

图中上面是用PCA算法把28 * 28的图像压缩成2维以及还原成28 * 28的效果。
图中下面是用深度自编码器把把28 * 28的图像压缩成2维以及还原成28 * 28的效果。
从结果上看,深度自编码器的效果更好。
用于text检索
- 把原文压缩成一个向量
- 把问题也压缩成一个向量
- 找到与问题最接近的原文向量

用于图像检索
- 把图像编码成c
- 基于c作检索
用于pre-training DNN — Greedy Layer-wise Pre-training
Greedy Layer-wise Pre-training:用于有大量unlabelled data和少量labelled data的场景。
如果目标是训练这样一个网络:
那么预训练过程如下:
- 训练一个auto-encoder:
$x$是输出,$\tilde x$是输出。目标是$x$与$\tilde x$尽量接近。hidden layer第1层的activation为code。
**Tips:**如果hidden layer的unit数比上一层要多,则需要在这一层加上一个很强的正则化,以防这一层“什么都不做”。 - 训练完去掉decoder部分,fix住encoder部分的weights为W1

- 再训练一个auto-encoder:
输出第一个auto-encoder得到的c,命令为向量$a^1$。输出是$\tilde a^1$。目标是$a^1$和$\tilde a^1$尽量接近。hidden layer第1层的参数不更新。hidden layer第2层的activation为code。
- 训练完去掉decoder部分,fix住encoder部分的weights为W2

- 现在已经有两个参数fix的hidden layer,用同样的方法pre-training第三个hidden layer,并fix住参数为W3。

- 至此为止pre-training结束,把真实的输出接在hidden layer 3后面。W1、W2、W3用之前fix住的值,W4随机初始化。然后正常训练。

提升auto-encoder的效果

deep auto-encoder解码器的应用
用于CNN生成图像

怎样做unpooling操作?
方法一:
pooling时记录数据来自原图哪个位置
unpooling时恢复原图大小,把值也恢复到记录的位置。其它位置置0。
方法二:
pooling时不需要记录位置。
unpooling时都恢复成相同的值。
怎样做Deconvolution?
Deconvolution就是Convolution.

怎样生成图像?

在c的向量空间选择一些点,经过decoder生成图像。
Deep Learing VS Structured Learning
Deep Learning是指RNN、LSTM、DNN等技术
Structured Learning是指HMM、CRF、SVM、感知机等技术
| Deep Learning | Structured Learning |
|---|---|
| 无向的RNN不考虑整个序列 | 使用viterbi[?],需要考虑整个序列 |
| 难以考虑label dependency | 可以结合label dependency |
| cost不能反映error | cost能反应error |
| Deep | Linear |
DL效果更好,但SL也很重要,常常将两者结合,能得到比较好的效果。
DL与SL结合的例子:
- 语音识别:CNN/LSTM/DNN + HMM
HMM公式:
$$ P(x, y) = P(y_1|start)\prod_{l=1}^{L-1}P(y|l+1|y_l)P(end|y_L)\prod_{l=1}^LP(x_l|y_l) $$
将HMM应用于语音识别,那么x代表声音信号,y代表语音辨识的结果。
公式中第一个连乘代表transition部分。这一部分由HMM训练。
第二个连乘代表initial部分。这一部分由DL提供。
$$
P(x_l|y_l) = \frac{P(y_l|x_l)P(x_l)}{P(y_l)}
$$
公式中,$P(y_l|x_l)$由DL训练,P(x_l)可以忽略,因为$x_l$代表输入,$P(y_l)$通过统计可得。
2. semantic tagging:双向LSTM + CRF/Structured SVM
先用RNN找出feature
由这些feature定义$\phi(x, y)$
$\phi(x, y)$用于CRF/SVM
is structured learning practical
1:22’12’’,这部分没听懂
VAE (Variational AutoEncoder)
背景:从 AutoEncoder 到 VAE
AutoEncoder 的局限性
传统的 AutoEncoder 存在以下问题:
- 不能生成新样本:只能重建输入,无法从潜在空间生成新样本
- 潜在空间不连续:相近的潜在向量可能解码出完全不同的图像
- 没有概率解释:无法给出生成样本的概率
VAE 的核心思想
VAE (Variational AutoEncoder) 通过引入概率分布来解决上述问题:
- AE: $z = \text{Encoder}(x)$ → 确定的向量
- VAE: $z \sim q_\phi(z|x)$ → 概率分布中采样
核心概念
1. 潜在空间正则化
VAE 不仅学习重建输入,还要求潜在变量的分布接近某个先验分布(通常是标准正态分布):
$$p(z) = \mathcal{N}(0, I)$$
2. 编码器的输出
VAE 的编码器输出不是单一的向量,而是分布的参数:
Encoder 输出:
- μ (mean): 分布的中心
- σ (std): 分布的宽度
- z ~ N(μ, σ²): 从分布中采样
3. 解码器的输入
解码器接收从潜在分布中采样得到的向量:
$$\hat{x} = \text{Decoder}(z), \quad z \sim \mathcal{N}(\mu, \sigma^2)$$
数学推导
变分推断 (Variational Inference)
目标:最大化数据的对数似然 $\log p_\theta(x)$
由于后验 $p(z|x)$ 难以计算,使用变分分布 $q_\phi(z|x)$ 来近似。
ELBO (Evidence Lower Bound)
VAE 最大化以下目标(ELBO):
$$\mathcal{L} = \mathbb{E}{q\phi(z|x)}[\log p_\theta(x|z)] - D_{KL}(q_\phi(z|x) || p(z))$$
| 项 | 名称 | 作用 |
|---|---|---|
| $\mathbb{E}{q\phi(z | x)}[\log p_\theta(x | z)]$ |
| $D_{KL}(q_\phi(z | x) |
KL 散度的计算
当 $q_\phi(z|x) = \mathcal{N}(\mu, \sigma^2)$ 且 $p(z) = \mathcal{N}(0, I)$ 时:
$$D_{KL}(q_\phi(z|x) || p(z)) = -\frac{1}{2}\sum_{j=1}^{J}(1 + \log\sigma_j^2 - \mu_j^2 - \sigma_j^2)$$
重参数化技巧 (Reparameterization Trick)
问题
直接从 $\mathcal{N}(\mu, \sigma^2)$ 采样是不可导的,无法反向传播。
解决方案
将采样过程分解为:
$$z = \mu + \sigma \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
graph LR
x[输入 x] --> Encoder
Encoder --> mu[μ]
Encoder --> sigma[σ]
epsilon[ε ~ N(0,I)] --> z
mu --> z
sigma --> z
z --> Decoder
Decoder --> x_hat[输出 x̂]
代码实现
def reparameterize(mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std) # ε ~ N(0, 1)
return mu + eps * std # z = μ + σ * ε
训练算法
VAE 训练流程
1. Sample x from training data
2. Encode: (μ, σ) = Encoder(x)
3. Reparameterize: z = μ + σ ⊙ ε, ε ~ N(0,I)
4. Decode: x̂ = Decoder(z)
5. Compute loss:
- Reconstruction: ||x - x̂||² or BCE(x, x̂)
- KL: -0.5 * Σ(1 + log(σ²) - μ² - σ²)
6. Backprop and update
完整损失函数
def vae_loss(x, x_hat, mu, logvar):
# Reconstruction loss
BCE = F.binary_cross_entropy(x_hat, x, reduction='sum')
# KL divergence
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
VAE 的变体
1. β-VAE
增加 KL 项的权重,学习更解耦的表示:
$$\mathcal{L} = \text{Reconstruction} + \beta \cdot \text{KL}, \quad \beta > 1$$
2. Conditional VAE (CVAE)
引入条件信息实现可控生成:
$$\mathcal{L} = \mathbb{E}{q\phi(z|x,c)}[\log p_\theta(x|z,c)] - D_{KL}(q_\phi(z|x,c) || p(z))$$
3. Vector Quantized VAE (VQ-VAE)
使用离散的潜在变量,适用于序列建模和图像生成。
4. Hierarchical VAE
多层潜在变量,捕捉不同层次的特征。
VAE vs GAN
| 特性 | VAE | GAN |
|---|---|---|
| 生成质量 | ⚠️ 较模糊 | ✅ 清晰 |
| 训练稳定性 | ✅ 稳定 | ❌ 需要技巧 |
| 潜在空间 | ✅ 连续、可插值 | ⚠️ 可能不连续 |
| 概率解释 | ✅ 有 | ❌ 无 |
| Inference | ✅ Encoder 推断 | ❌ 需要额外训练 |
| 应用 | 表示学习、异常检测 | 图像生成、编辑 |
应用场景
1. 图像生成
生成新的、类似的样本。
2. 异常检测
重建误差大的样本为异常:
$$\text{Anomaly Score} = ||x - \hat{x}||^2$$
3. 图像修复 (Inpainting)
给定部分图像,重建完整图像。
4. 表示学习
学习解耦的潜在表示,用于下游任务。
5. 数据增强
生成合成数据扩充训练集。
实践技巧
1. KL Annealing
训练初期减小 KL 权重,避免“posterior collapse“:
$$\mathcal{L} = \text{Reconstruction} + w(t) \cdot \text{KL}$$
$w(t)$ 从 0 逐渐增加到 1。
2. 重建损失选择
| 数据类型 | 推荐损失 |
|---|---|
| 归一化图像 | BCE (Binary Cross Entropy) |
| 自然图像 | MSE 或 Perceptual Loss |
| 文本 | Cross Entropy |
3. 潜在空间维度
- 太小:重建质量差
- 太大:后验坍塌 (posterior collapse)
- 常用:16 ~ 256
代码结构示例
import torch
import torch.nn as nn
class VAE(nn.Module):
def __init__(self, latent_dim=20):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(784, 400),
nn.ReLU(),
)
self.fc_mu = nn.Linear(400, latent_dim)
self.fc_logvar = nn.Linear(400, latent_dim)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 400),
nn.ReLU(),
nn.Linear(400, 784),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
相关链接
- Common/AutoEncoder.md - 基础 AutoEncoder
- GenerativeModels/CVAE.md - 条件 VAE
- GAN/VAEGAN.md - VAE 与 GAN 结合
参考资料
- Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. ICLR.
- Doersch, C. (2016). Tutorial on Variational Autoencoders. arXiv.
CVAE (Conditional Variational AutoEncoder)
背景:从 VAE 到 CVAE
VAE 的局限性
VAE (Variational AutoEncoder) 是一种无条件生成模型:
- 输入:随机噪声 $z \sim \mathcal{N}(0, 1)$
- 输出:生成的样本 $x$
问题:无法控制生成的内容,完全随机。
CVAE 的核心思想
CVAE (Conditional VAE) 通过引入条件信息来实现可控生成:
- 输入:条件 $c$ + 随机噪声 $z$
- 输出:基于条件 $c$ 生成的样本 $x$
$$p_\theta(x|c) = \int p_\theta(x|z,c)p(z)dz$$
模型结构
VAE vs CVAE
VAE:
Encoder: x → q_ϕ(z|x)
Decoder: z → p_θ(x)
CVAE:
Encoder: (x, c) → q_ϕ(z|x,c)
Decoder: (z, c) → p_θ(x|c)
网络架构
graph LR
c[条件 c] --> Encoder
x[输入 x] --> Encoder
Encoder --> z[潜在变量 z]
z --> Decoder
c --> Decoder
Decoder --> x_hat[重建 x̂]
数学推导
VAE 的 ELBO (Evidence Lower Bound)
VAE 最大化以下目标:
$$\mathcal{L}{VAE} = \mathbb{E}{q_\phi(z|x)}[\log p_\theta(x|z)] - D_{KL}(q_\phi(z|x) || p(z))$$
CVAE 的 ELBO
将条件 $c$ 加入每一项:
$$\mathcal{L}{CVAE} = \mathbb{E}{q_\phi(z|x,c)}[\log p_\theta(x|z,c)] - D_{KL}(q_\phi(z|x,c) || p(z|c))$$
通常假设 $p(z|c) = p(z) = \mathcal{N}(0, I)$,即先验与条件无关。
重参数化技巧 (Reparameterization Trick)
为了能够反向传播,使用重参数化:
$$z = \mu_\phi(x,c) + \sigma_\phi(x,c) \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
训练算法
CVAE 训练流程
1. Sample (x, c) from training data
2. Encode: (μ, σ) = Encoder(x, c)
3. Reparameterize: z = μ + σ ⊙ ε, ε ~ N(0,I)
4. Decode: x̂ = Decoder(z, c)
5. Compute loss:
- Reconstruction loss: ||x - x̂||²
- KL divergence: -log(σ) + 0.5(μ² + σ² - 1)
6. Backprop and update
损失函数
$$\mathcal{L} = \underbrace{||x - \hat{x}||^2}{\text{Reconstruction}} + \underbrace{\beta \cdot D{KL}(q_\phi(z|x,c) || p(z))}_{\text{Regularization}}$$
CVAE 的应用
1. 条件图像生成
给定类别标签生成对应图像:
- 条件 $c$:类别标签(如“猫“、“狗”)
- 输出 $x$:对应类别的图像
2. 对话生成
给定上下文生成回复:
- 条件 $c$:上文句子
- 输出 $x$:回复句子
3. 图像修复 (Inpainting)
给定部分图像修复完整图像:
- 条件 $c$:不完整的图像
- 输出 $x$:完整的图像
4. 超分辨率
给定低分辨率图像生成高分辨率图像:
- 条件 $c$:低分辨率图像
- 输出 $x$:高分辨率图像
5. 多模态生成
给定一种模态生成另一种模态:
- 条件 $c$:文本描述
- 输出 $x$:图像
CVAE vs 其他生成模型
| 模型 | 条件生成 | 采样速度 | 生成质量 | 训练稳定性 |
|---|---|---|---|---|
| CVAE | ✅ | ✅ 快 | ⚠️ 中等 | ✅ 稳定 |
| CGAN | ✅ | ✅ 快 | ✅ 好 | ❌ 不稳定 |
| Diffusion | ✅ | ❌ 慢 | ✅✅ 最好 | ✅ 稳定 |
实践技巧
1. β-CVAE
增加 KL 项的权重,学习更解耦的表示:
$$\mathcal{L} = \text{Reconstruction} + \beta \cdot \text{KL}, \quad \beta > 1$$
2. 条件编码方式
| 方式 | 说明 | 适用场景 |
|---|---|---|
| Concat | 将 $c$ 与输入拼接 | 通用 |
| FiLM | 用 $c$ 生成缩放和平移参数 | 图像生成 |
| AdaIN | 条件实例归一化 | 风格迁移 |
3. 潜在空间插值
在潜在空间插值可以生成平滑过渡的样本:
$$z_\alpha = \alpha \cdot z_1 + (1-\alpha) \cdot z_2$$
代码结构示例
class CVAE(nn.Module):
def __init__(self, latent_dim, condition_dim):
self.encoder = Encoder(latent_dim, condition_dim)
self.decoder = Decoder(latent_dim, condition_dim)
def forward(self, x, c):
mu, logvar = self.encoder(x, c)
z = self.reparameterize(mu, logvar)
x_hat = self.decoder(z, c)
return x_hat, mu, logvar
def sample(self, c, n_samples):
z = torch.randn(n_samples, self.latent_dim)
return self.decoder(z, c)
相关链接
- Common/AutoEncoder.md - 基础 AutoEncoder
- GAN/VAEGAN.md - VAE 与 GAN 结合
- GAN/Condition.md - 条件 GAN
参考资料
- Sohn, K., Yan, X., & Lee, H. (2015). Learning Structured Output Representation using Deep Conditional Generative Models. NeurIPS.
- Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. ICLR.
方法一:Pixel RNN
每次使用RNN生成一个像素,直至最后生成一整张图。
一个像素用一个向量表示。
优点:无监督学习,训练时只需要输入图像,不需要annotation。
这种方法也可以用于语音合成或视频生成。
Tip:
想要生成的图像颜色鲜明,像素的RGB三个值要差别够大。如果三个值差不多大,生成的图像是灰色的。
如果使用向量$[R, G, B]^\top$来代表一个像素,向量的值由sigmoid生成。sigmoid倾向于落在0.5附近,使得RBG值都差不多,生成出的图像是“水墨风”。
改进方法:
用1 of N encoding方法表示像素的颜色
方法二:VAE
模型结构
VAE = Viational auto encoder
对比Auto Encoder的模型:
VAE的模型为:
- NN encoder生成2个向量,分别是$m$和$\sigma$
- 基于标准正态分布生成随机向量e
- $C_i = \exp(\sigma_i) \times e_i + m_i$
- 目标增加一项,最小化
$$ \sum_i(1+\sigma_i - (m_i)^2 - \exp(\sigma_i)) $$
VAE的应用
可以控制要画的image
假如中间生成的c是10维的,
- 输入一张图像,得到10维的向量c
- 固定其中8维
- 在剩下的2维空间中均匀取点,每个点结合第2步中的8维都可以生成一张图像。
- 观察每个维度的变化对生成图像的意义。
缺点:生成的结果不太清晰
用于语音可以生成文本
使用上图的模型,但输入和输出都是同一个句子的向量。
- 任意找两个句子,把它们映射到code空间,得到两个点
- 将两点相连,中间等间隔取点
- 把中间的点用decoder还原,生成新的句子
VAE的原理
直观解释

对普通auto-encoder,一个输入对应一个code,通过code能生成与输入相同的输出。如果两个输入分别得到两个code,很难约束两个code的中间向量应该输出什么。
在VAE算法中:
- encoder阶段:一个输入计算出它的真实code以后,会在这个code上加一点noise,作为它最终的code。
- decoder阶段:期望code加上noise之后的向量(一个范围内的向量)都能decode出原始图像。
由于noise的随机性,code + noise代表一个范围内的所有向量。
这样,两张原图得到的code范围可以有交叠,交叠部分的向量decode出来的图像应该同时像两张图,即两张图的中间结果。
模型中的目标函数$\sum_{i=1}^3(1+\sigma_i - (m_i)^2 - \exp(\sigma_i))$:
m: 图像生成的code
c: m加上noise之后的code
$\sigma$:noise的方差,exp是为了保证方差一定是正的。
$(m_i)^2$代表L2正则化
$\exp(\sigma_i) - (1-\sigma_i)$:画图可以看出这个函数的效果。 目标是让noise的方差不要太小。
公式解释
假设每张图像都是高维空间中的X
目标是评估P(x)分布,然后根据P(x)分布sample出一张图
假设P(x)符合高斯混合模型,即
$$
P(x) = \sum_m P(m)P(x|m)
$$
其中,每个m代表一个高斯分布,P(m)代表第m个高斯分布出现的概率。p(x|m)代表第m个高斯分布中sample出x的概率。
这里的m符合Multinoulli 分布。但在VAE中,M本身也是一种连续型的分布z。
$$
\begin{aligned}
P(z) \sim N(0, 1) \
P(x|z) \sim N(\mu(z), \sigma(z))
\end{aligned}
$$
这个模型可以看作是有无数个高斯模型的混合。而$\mu(z), \sigma(z)$由encoder训练得出。实际上P(x|z)也可以是其它模型。因为NN可以拟合出任意模型。
$$
P(x) = \int_z P(z)P(x|z)dz
$$
目标是最大化已经观察到的x的概率:
$$
L = \sum_x\log P(x)
$$
公式推导过程略,最后结果是:最小化以下公式
$$
-KL(q(z|x)||p(z)) + \int_z a(z|x)\log p(x|z)dz
$$
公式的第一项代表最大化分布q(z|x)和分布p(z)的KL散度,化简出来就是前面提到的$\sum_{i=1}^3(1+\sigma_i - (m_i)^2 - \exp(\sigma_i))$。
公式第二项代表encoder与decoder的交叉熵,即输入和输出越接近越好。
VAE的缺点
只能产生一张与database一样的image,或者把database中的image融合到一起。 — 模仿
不能产生一张全部的image。 — 创造
方法三: GAN Generative Adversarial Network
原理

上面的蝴蝶代表Generative模型,用于生成结果。
下面的鸟代表Descriminator模型,用于鉴别结果是真实的还是由G模型生成的。
G模型和D模型势均力敌,互相促进,最终都得到了进化。
训练步骤
- G0随机生成一些图像
- D使用真实图像和G0生成的图像来更新参数,得到一个能鉴别G0的D0。
- G0更新参数,目标是得到能在D0上得到高分(骗过D)的G1。
- D再根据真实图像和G1训练出D1。
- 如此反复,直至G能产生高质量的图像。
在这个过程中,只有D见过database的图像,G没有见过。G只是不断是尝试骗过D。所以G能创建图像。
GAM的难点
- 难以优化
- 难以判断G的好坏。如果D不能识别G,不一定是因为G太强,也有可能是因为D太弱了。
- 平衡G和D的关系,保持势均力敌。
根据Text生成Image
传统的监督学习方法

存在的问题:
同一个输入在database中可能同时对应多种输出。
训练的结果会输入各种可能的平均。所致结果很糊而不伦不类。
Conditional GAN的学习方法
生成网络G和鉴别网络D:
存在的问题:
G只要产生出足够高质量的图像,就可以骗过D。但这个高质量的图像很可能入输入的条件无关。
高质量但与输入无关的图像也应该是false的图像。现在D无法鉴别这种情况。
最后G会生成高质量但无视输入的图像。
改进的Conditional GAN
改进方法:
网络D的输入同时考虑G的输入c和G的输出x。
D的判断G输出是否合理的标准有:
(1)x是否高质量
(2)c和x是否match
定义一个样本为{c, x}对,其中c是输入的条件,这里就是文本,x是生成的目标,这里就是指图像。
- part 1 训练D
- 从database中sample出m个positive样本。
- 随机生成m个noise图像,配上step1中positive样本的文字,得到的是m个负样本。
- 在从database中再sample出m个真实图像,配上step1中positive样本的文字,又得到的是m个负样本。
- 更新D的参数以最大化:
V = 第1组样本的平均分 + (1-第2组样本的平均分) + (1-第3组样本的平均分)
- part 2 训练G
- 生成m个随机图像z
- 从database中随机sample出m个文本c
- 更新G的参数,只(c, z)在D中的分数越高越好
网络D的两种结构:
Stack GAN
先生成小张图,再根据小张图生成大张图
根据Image生成Image
例子:
传统的监督学习方法
同text to Image
条件GAN
同text to Image
patch GAN
当要生成的image很大时,让D每次只检查image的一小块。
其它应用
用于语音增强
用于vedio生成
应用:风格转换
这种类型的Task没有原风格与生成风格的数据对,只能用无监督学习。
Direct Transformation

这种方法只能做小的改动,例如文字、颜色等
Projection to Common Space

假设要生成的x是高维空间中的一个点
在高维的Image Space中,只有一小部分点example出来是合理的。
即:要产生的x符合一个固定的distribution。目标是找出这个distribution。
定义目标distribution为$P_{\text{data}}(x)$
在GAN之前,使用最大似然估计来找$P_{\text{data}}(x)$

- 定义一个distribution $P_G(X;\theta)$
- 调整$\theta$,使$P_G$与$P_{\text{data}}(x)$越接近越好。
- 2.1 从$P_{\text{data}}(x)$中sample出m个点$x_i$
- 2.2 计算$P_G(x_i; \theta)$
- 2.3 定义最大似然估计公式$L = \prod_{i=1}^mP_G(x_i;\theta)$
- 2.4 找出最大化L的参数$\theta^*$
最大似然估计 = 最小KL散度
$$ \begin{aligned} \theta^* &=& \arg\min_{\theta} \prod_{i=1}^mP_G(x_i;\theta) \ &=& \arg\min_{\theta} KL(P_{\text{data}}||P_G) \end{aligned} $$
后面的我也不知道在讲什么,只是把讲的内容记下来
$$ \begin{aligned} G* = \arg\min_G \text{Div}(P_G, P{\text{data}}) \end{aligned} $$
公式中的$P_G$未知,所以无法直接比较这两个分布的KL散度
从$P_G$和$P{\text{data}}$各sample出一些data
$$
V(G, D) = E_{X\sim P{\text{data}}}[\log D(x)] + E_{X\sim P{\text{G}}}[\log (1-D(x))]
$$
在计算公式过程中:
D(x)可以是任意function,通常是由NN训练得到。
分布$P_G$是固定不变的。
解以上公式得:
$$
\begin{aligned}
D^* &=& \arg\max_D V(D, G) \
&=& \arg\max_D P{\text{data}}(x) \log D(x) + P_G(x) \log(1-D(x)) \
&=& \arg\max_D a \log D + b \log (1-D)
\end{aligned}
$$
说明:上面公式中,为了简化计算,人为定义出:
$$
\begin{aligned}
a &=& P{\text{data}}(x) \
b &=& P_G(x) \
D &=& D(x) \
f(D) &=& a \log D + b \log (1-D)
\end{aligned}
$$
直接寻找f(D)偏导为0的点:
令$\frac{df(D)}{dD} = 0$,得:$D^* = \frac{a}{a+b}$
把$D^$代入V(G,D)得:
$$
\begin{aligned}
V(G, D^) &=& -2\log 2 &+& KL(P{\text{data}}||\frac{P{\text{data}}+P_G}{2}) + KL(P{\text{G}}||\frac{P{\text{data}}+P_G}{2}) \
&=& -2\log 2 &+& 2JSD(P{\text{data}}||P_G)
\end{aligned}
$$
公式中,JSD代表Jesen-Shannon Divergence
上面提到公式G的计算: $$ \begin{aligned} G^ = \arg\min_G \text{Div}(P_G, P{\text{data}}) \end{aligned} $$
G无法直接计算,根据上面的推导得到:
$$
\begin{aligned}
G^ = \arg\min_G\max_D V(G, D) \
D^* = \arg\max_D V(G, D)
\end{aligned}
$$
怎么理解上面这两个公式:
图中红点代表能使V(D, G)最大的$D^$
G3是这三个中最优的G。
训练步骤:
- 初始化G和D
- 迭代
- 2.1 固定住G,更新D
- 2.2 固定住D,更新G
由于计算$G^* = \arg\min_G\max_D V(G, D)$这一步要求固定住D,因此定义loss function为:
$$
L(G) = \max_D(V, G)
$$
问:带max的分段函数怎么求导?
答:以下图为例:
$$
\frac{df(x)}{dx} = \frac{df_i(x)}{dx}
$$
if $f_i(x)$ is the max one。
求G*的迭代过程没看懂,直接上图:
后面就放弃了
通用框架 = fGAN = framework of GAN
这是一种数学很NB但实际效果不怎么样的一种技术。
f-divergence
https://windmissing.github.io/mathematics_basic_for_ML/Information/Divergence.html#f-divergence
$$ \begin{aligned} D_f(P||Q) = \int_x q(x) f\left(\frac{p(x)}{q(x)}\right) && (1) \end{aligned} $$
f(x) is convex && f(1) = 0
Fenchel Gonjugate
https://windmissing.github.io/mathematics_basic_for_ML/Mathematics/function.html
$$ \begin{cases} f^(t) = \max_{x\in dom(f)}{xt - f(x)} && (2)\ f(x) = \max_{x\in dom(f^)}{xt - f^*(t)} && (3) \end{cases} $$
GAN
由于公式(1)中的f函数是convex的,所以可以用f(x)的conjugate function来表示它。即把公式(3)代入公式(1),得:
$$
D_f(P||Q) = \int_x q(x)\left(\max{\frac{p(x)}{q(x)}t - f^*(t)}\right)dx
$$
t是什么?
GAN的目标是希望网络D的输入是x,输出是t,所以可以用D(x)代替t,得:
$$ \begin{aligned} D_f(P||Q) &\ge& \int_x q(x)\left(\max{\frac{p(x)}{q(x)}D(x) - f^(D(x))}\right)dx \ &\approx& \max_D \int_x p(x)D(x)dx - \int_x q(x) f^(D(x))dx \ &=& \max_D {E_{x\sim P}\left[D(x)\right] - E_{x\sim Q}\left[f^*\left(D(x)\right)\right]} && (4) \end{aligned} $$
以上公式中,
- 分布P代表GAN中的$P_{\text{data}}$
- 分布Q代表GAN中的$P_{\text{G}}$
- f* 可以取不同的divergence,当$f^*(t) = \exp(t-1)$时,对应的是KL divergence。
网络G的目标是:最小化$D_f(P_{\text{data}}||P_{\text{G}})$,即
$$
\begin{aligned}
G^* = \arg\min_G D_f(P_{\text{data}}||P_{\text{G}}) && (5)
\end{aligned}
$$
可以将公式(4)代入公式(5)来求G*
使用不同的$f*$将得到不同的$G*$和$D*$
为什么要使用不同的divergence?
传统的GAN存在两个问题
- Mode Collapse:
指generated data分布越来越集中。
表现为:随机迭代次数的增加,某个特定的generated data开始蔓延
- Mode Dropping:
指Pdata有两群,generated data只能学到其中一群。
例如生成人脸每次只能生成一种肤色:
以上问题的原因(猜测):Divergence选得不好
观察先不同Divergence对PG拟合Pdata的效果影响。
- KL Divergence

假设Pdata的分布与图中蓝线的分布相同。使用KL divergence拟合的PG为图中绿线的效果。
表现为G很糊,不伦不类。
传统的生成算法使用最大似然估计,就会出现这种现象。
- reverse KL Divergence

PG只能指使Pdata中的部分分布,导致某一些特定的x的PG特别高,而令一些x的PG特别低。
本文前几面介绍的GAN使用的divergence类似这种。因此会出现Mode Collapse和Mode Dropping的情况。
Mode Collapse可以看作是Mode Dropping的一种极端情况。
解决方法
理论上更换divergence可以解决以上问题。
事实上这种方法不太有用。
LSGAN = Least Square GAN
PG和Pdata这两个分布没有重叠
解释一:
因为Img是高维在低维上的manifold,因此即使两个Img在低维上重叠,它们在高维上也是可以分开的。
解释二:
PG和Pdata的分布本身可能是重叠的,它们实际在公式中使用的是PG和Pdata的sample,它们是不重叠的。
PG和Pdata不重叠会有什么问题
对于两个不重叠的分布,应该使用分布之间的距离来衡量它们之间的相似度。
当前GAN公式中使用的是JS Divergencelink
对于JS Divergence,两个不重叠的分布的JSD永远是log2。如上图三种情况,图1和图2没有重叠,JSD是log2,图三完全重叠,JSD是0。
这带来的问题时,当PG和Pdata为图1的关系时,它不知道要如果改进。也不知道图2是比图1更好的结果。
解决方法
linear代替sigmoid,将分类问题变成了回归问题。
WGAN = Wasserstein GAN
WGAN的主要改进
-
更新G的参数过程中,用Earth Mover’s Divergence代表JS Divergence WGAN可以解决不overlap情况下Divergence不变的问题。
-
更新D的参数过程中,增加1-Lipschitz限制,得到PG到Pdata可以平滑过渡
Earth Mover’s Divergence
case 1

W(P, Q) = d
case 2

分布如图P、Q所有,可以构造不同的move plan把P变成Q,不同的move plan会得到不同的距离,例如:
因此需要穷举所有的move plan找到最小的move plan。
定义某个move plan为$\gamma$,$B(\gamma)$为对应的距离:
$$
\begin{aligned}
B(\gamma) = \sum_{x_p, x_q}\gamma(x_p, x_q)||x_p-x_q|| \
W(P, Q) = \min B(\gamma)
\end{aligned}
$$
例如这里个case中最好的move plan是这样的:
W可以解决JS在不overlap情况下距离不变的问题。
1-Lipschitz限制
为什么限制
D的目标增加Pdata的D(x),减小PG的D(x)。
但只是这样的目标,可能永远无法收敛,因为左边可以无限下降而右边可以无限上升。
到最后左边跟右边之间差距非常大而形式悬崖,悬崖导致难以从左边优化到右边。
因此增加D的形状限制,要求D是平滑的。1-Lipschitz就是一种平滑限制。
Lipschitz平滑定义为:
$$
||f(x_1)-f(x_2)|| \le K||x_1-x_2||
$$
当K为1时,称为1-Lipschitz平滑。
怎么限制
论文作者没有很的方案,只是建议weight clipping。
这种方法不一定能真的实现1-Lipschitz限制。
WGAN-GP的主要改进
改进一
在WGAN的基础上,提供了一种实现1-Lipschitz限制的方法。
原理:
$D \in$1-Lipschitz等价于$||\nabla_x D(x)||\le 1$for all x
for all x意味着要遍历所有的可能,即:
$$
V(G, D) = \max\left(V(G, D), \lambda\int_x \max(0, ||\nabla_xD(x)||-1)dx\right)
$$
公式中\int_x即代表遍历所有的可能,但这是不可行的,因此公式改为:
$$
V(G, D) = \max\left(V(G, D), \lambda E_{x\in P_{\text{penalty}}}\left[\max(0, ||\nabla_xD(x)||-1)\right]\right)
$$
什么是$x\in P_{\text{penalty}}$?
- 在PG和Pdata中各任意取2个点。
- 两个点分别连线
- 连线上随机sample的点就是penalty
改进二
WGAN中为了让D平滑,只惩罚了梯度>1的情况,而不care梯度<的情况。
实验结果表明,梯度越接近1效果越好。因为V(G,D)公式改为:
$$
V(G, D) = \max\left(V(G, D), \lambda E_{x\in P_{\text{penalty}}}\left[(||\nabla_xD(x)||-1)^2\right]\right)
$$
Spectrum Norm
Keep gradient norm smaller than 1 everywhere
怎么把GAN改成WGAN

EBGAN
EBGAN = Energy-based GAN
使用auto-encoder作为D
原理:
一张图如果越成recontruct,则说明它的质量越高。
优点:可以pre-train D。这样G在一开始就很强,使的G在初期提升很快。
GAN-LSGAN
loss-sensitive GAN

Info GAN
- 把input vector分成两个向量:c和z’
- 增加一个组件classifier
classifier根据G生成的x来预测输入的c
Generator + Classifier类似一个相反的auto-encoder - Discriminator用于检测G的结果好不好

C和D只有最后一部分不同,前面部分共享参数。
加入Classifier的好处:
C必须对x有clear的influence。
z’代表纯随机的无法解释的部分。

从VAE的角度看,加上D使用decoder的图像质量更高。
从GAN的角度看,加上encoder,可以使学习有个目标,学习效果更稳定。
Encoder的目标:
- 最小化reconstructure error
- z to normal
Decoder的目标: - 最小化reconstructure error
- 难过D
D的目标:
区分是生成的Img还是reconstructed Img。
训练步骤
- 初始化En, De, Dis
- 从database sample出M张图像,计做x
- $\tilde z = En(x)$
- $\tilde x = De(\tilde z)$
- 从某个分布(例如正态分布)中sample出M个code向量,记做z
- $\hat x = De(z)$,此时有三种Img,分别是(2)database sample出来的(4)x经过auto-encoder重新生成的(6)decoder随机生成的
- 更新En的参数,目标:$||\tilde x -x ||\downarrow$,KL$(P(z|x)||P(z))\downarrow$
- 更新De的参数,目标:$||\tilde x -x ||\downarrow$,Dis$(\tilde x)\uparrow$,Dis$(\hat x)\uparrow$
- 更新Dis的参数,目标::$||\tilde x -x ||\uparrow$,Dis$(\tilde x)\uparrow$,Dis$(\hat x)\downarrow$

把Encoder和Decoder分开,不是串联,而是并联。
Encoder:输入sample的真实图像x,输出生成的code z
Decoder:输入某分布sample出的code z,输出生成的图像x
Discriminator:输入一对(x, z),D辨别这一结数据来自Encoder还是Decoder
训练过程
- 从database sample出M张图像,记为x
- $\tilde z = En(x)$
- 从某分布sample出M个code,记为$z$
- $\tilde x = De(z)$
- 更新Dis的参数,目标:Dis$(x, \tilde z)\uparrow$,Dis$(\tilde x, z)\downarrow$
- 更新En和De的参数,目标:Dis$(x, \tilde z)\downarrow$,Dis$(\tilde x, z)\uparrow$
En和De联手骗过Dis
BiGAN的原理
设联合分布$(x, \tilde z)$为P,$(\tilde x, z)$为Q
希望通过Dis的引导,让P和Q越接近越好。
普通auto-encoder得到的图像:不清晰,且跟原图很像
BiGAN得到的图像:清晰,且跟原图不像
Triple GAN

用于半监督学习
用于图像
训练集与测试集不match的场景:
解决方法:
用Generator从Image中抽feature
feature满足同样的分布,它们是match的。
网络结构:
其中Domain Classifier相当于一个Discriminator
用于语音
以语音seq2seq为例:
一段音频包含了许多信息,例如发音信息,环境信息,语者信息。
把不同的信息提取出来可以有不同的应用:
发音信息 — 语音识别,语者信息 — 声纹比对
提取方法:

原理类似于DAT
照片编辑应用
已知有一个G,可以根据G的向量z生成图像x。
那么怎么找到z?
解决方法:
利用G训练一个encoder,利用D初始化encoder
对于一张输入图像Image:
- 用以上方法反推出它的vector
- 以调头发长短为例,把所有短发Imge的vector取平均,得到v1,把所有长发Imge的vector取平均,得到v2
- v2 - v1 = 修改头发长短的向量,$z_{long} = \frac{1}{N_1}\sum_{long}En(x) - \frac{1}{N_2}\sum_{short}En(x)$
- 短发 x -> En(x) + z_long -> z’ -> G(z’)长发
条件序列生成,例如:文字转语音、翻译、Chatbot
可以用传统的seq2seq解决,也可以用GAN解决。
以Chatbot为例,seq2seq的做法是:
这种方法存在的问题:
对于How are you这样的提问,通常的回归是I’m fine。如果回答Not bad也是可以的。但使用最大似然方法,机器会认为I’m John比Not bad更合适。
条件序列生成的技术
技术一:Reinforcement Learning
复习一下policy Gradient

$$
\bar R_\theta = \sum_c P(c)\sum_x R(c, x)P_\theta(x|c)
$$
公式中的符号定义如下:
$\theta$:参数,在这些为固定值
$\bar R_\theta$:reward的期望
$\sum_c$: 遍历所有可能的condition
P(c):某个condition出现的几率
$\sum_x$:遍历所有可能的action
R(c, x):condition条件下某个action的reward
$P_\theta(x|c)$:given $\theta$和c时回应为x的几率
目标:调$\theta^*$,让$\bar R_\theta$最大:
$$
\begin{aligned}
\bar R_\theta = E_{c\in P(c), x \in P(\theta|c)}[R(c,x)] && (1)
\end{aligned}
$$
公式(1)中的$c\in P(c), x \in P(\theta|c)$无法穷举所有的以(c, x),因此用sample的(c1, x1), …, (cm, xm)代替:
$$
\begin{aligned}
\bar R_\theta \approx \frac{1}{N}\sum_i R(c^i,x^i) && (2)
\end{aligned}
$$
公式(2)中已经没有了参数$\theta$,$\theta$完全体现在了sample的数据中了。
下一步工作是计算$\bar R_\theta$对$\theta$偏导,这种情况就没法做偏导了。
解决方法:
先对公式(1)求偏导,然后再代入sample:
$$
\begin{aligned}
\bar R_\theta = E_{c\in P(c), x \in P(\theta|c)}[R(c,x)\nabla\log P_\theta(x|c)] && (3)
\end{aligned}
$$
sample代入公式(3)得:
$$
\begin{aligned}
\bar R_\theta \approx \frac{1}{N}\sum_iR(c^i,x^i)\nabla\log P_\theta(x^i|c^i) && (4)
\end{aligned}
$$
更新效果:
$$
\theta \leftarrow \theta + \eta\nabla\bar R_\theta
$$
如果$R(c^i,x^i) > 0$,则$P_\theta(x^i|c^i) \uparrow$
如果$R(c^i,x^i) < 0$,则$P_\theta(x^i|c^i) \downarrow$
每次更新过$\theta$后要重新sample data
最大似然法 VS 强化学习法
| Maximum Likelihood | Reinforement Learning | |
|---|---|---|
| 目标函数 Objective Function | $\frac{1}{N}\sum_i\log P_\theta(x^i\mid c^i)$ | $\frac{1}{N}\sum_i R(c^i, x^i)\log P_\theta(x^i\mid c^i)$ |
| Gradient | $\frac{1}{N}\sum_i\nabla\log P_\theta(x^i\mid c^i)$ | $\frac{1}{N}\sum_i R(c^i, x^i)\nabla\log P_\theta(x^i\mid c^i)$ |
| Training Data | 已有的标记数据 | 每次迭代之后sample的数据 |
技术二:GAN
RL是由人给feedback,GAN则是由D给feedback
D的output就是reward。
训练数据集:正确的(c, x)
训练步骤:
- 初始化G(chatbot)和D
- 从database sample出正确的(c, x)
- 从database sample出c’,计算$\tilde x = G(c’)$
- 更新D,使得$(c, x)\uparrow$,$(c’, \tilde x)\downarrow$
- 更新G(chatbot),使得$(c’, \tilde x)\uparrow$
其中G是一个seq2seq:
这里会有一个问题:此过程包含sampling,无法微分
解决方法: - Gunbel-softmax,一个数学trick
- Continuous Input for Doscriminator,避开sampling,把distribution交给D。此方法需要结合WGAN。

- Reinforcement Learning,把R换成D

$$ \begin{aligned} nabla \bar R_\theta \approx \frac{1}{N}D(c^i, x^i)\nabla \log P_\theta(x^i|c^i) && (5)\ \log P_{\theta}(c^i, x^i) = \log P(x_1^i|c^i) + \log P(x_2^i|c^i, x_1^i) + \log P(x_3^i|c^i, x_1^i, x_2^i) && (6) \end{aligned} $$
假如提问:ci = What’s your name?
回答:xi = I don’t known.
这个回答不合适,给了negative的reward,因此公式(6)中的每一项中的概率都要下降。
但其实第一项$P(x_1^i=I|c^i)$不应该下降,这个句子回答可以以I开关。
理论上,这不是一个问题,因为只要sample的次数足够多,会出现“I am John”这样的case把$P(x_1^i=I|c^i)$拉起来。
但实际上,这是一个问题,因为sample的次数永远都不会足够多。
解决方法:
$$
\nabla \bar R_\theta \approx \frac{1}{N}\sum_i\sum_t(Q(c^i, x_{1:t}^i)-b)\nabla \log P_\theta(x_t^i|c^i, x_{1:t}^i)
$$
其中$Q(c^i, x_{1:t}^i)-b$为对每个timestep做evaluation。
MLE VS GAN
MLE:喜欢回答I’m sorry或I’ don’t known这样通用的句子。这种回答对应于MLE图像生成算法中的模糊影像。
GAN:会生成更长更复杂的句子。但不一定更好。
条件序列生成的应用
应用一:Text Style Transfer
例如:
音频:男声转女声
文本:positive转negative
方法一:直接transfer

方法二: projection to common space

应用二:摘要提取
方法一
输入一篇文章,判断每个句子的重要性。
把重要的句子连起来就是这篇文章的摘要。
缺点:句子拼凑起来的摘要不好,要自己产生句子。
方法二:seq2seq
输入大量的(文章,摘要)对,训练一个seq2seq
缺点:需要大量的labelled data,百万级别
方法三:风格迁移
把文章和摘要看成是两种风格(domain)的文本。
只需要准备一堆文章和一堆摘要,而不需要文章和摘要有什么关系。
D用于保证生成出来的东西是摘要。
R用于保证生成出来的东西与输入有关。
Note:
先用非监督学习训练,再用labelled data做fine tune。
只需要少量的labelled data就可以得到与监督学习一样的效果。
应用三:机器翻译
把不同的语音视为不同的domain
也可以用于语音识别,把语音和文字视为不同的domain
方法一:用likelihood来衡量
$$ L = \frac{1}{N}\sum_i\log P_G(x_i) $$
其中:
$x_i$为从真实样本中sample出的data
$P_G(x_i)$为G产生数据xi的概率。实际上这个概率根本没法算
解决方法:用Kernal Density Estimation来估计$P_G(x_i)$
- 用PG产生大量data — 到底是多少data?
- 用高斯混合模型逼近这些data — 到底是多少个高斯模型?
- 用高斯混合模型估测$P_G(x_i)$
这个方法存在一些问题,除了上面提到的问题以外,还有一个关键问题:likelehood不一定能衡量PG的好坏。
方法二:Objective Evaluation
用一个off-the-shell的classifier来判断oject的好坏。
评分标准
- 单张图像够清晰
用classifier对一张图像做分类,得到属于各个类的概率组成的分布。
分布越集中,图像越清晰
- 整体够diverse
用G生成一组图像,分别对其中的每个图像做分类。
每个图像得到一个分布,把所有的分布都加起来,得到综合的分布。
综合分布越平均,整体越diverse。
把评分标准数字化
Inception score =
$$
\sum_x\sum_y P(y|x)\log P(y|x) - \sum_y P(y) \log P(y)
$$
公式第1项代表1的得分,第2项代表2的得分。
未解决的问题
如果GAN只是记住了database里的某些图像,而不是创造新图像,用这种方式识别不出来。
强化学习基础
核心概念
强化学习 (Reinforcement Learning, RL) 是一种通过与环境交互来学习最优行为的学习范式。
智能体 (Agent)
│
│ 观察状态 s_t
▼
环境 (Environment) ──→ 执行动作 a_t ──→ 获得奖励 r_t
│ │
└───────────────────────────────────────┘
环境状态更新
关键特点:
- 试错学习:通过尝试错误来学习
- 延迟奖励:当前动作可能影响未来的奖励
- 序列决策:需要考虑长期后果
与监督学习的对比
| 监督学习 | 强化学习 | |
|---|---|---|
| 数据来源 | 标注数据集 | 与环境交互 |
| 学习目标 | 预测标签/值 | 最大化累积奖励 |
| 反馈形式 | 正确答案 | 奖励信号(标量) |
| 时间依赖 | 通常独立同分布 | 序列依赖 |
| 典型应用 | 图像分类、翻译 | 游戏 AI、机器人控制 |
马尔可夫决策过程 (MDP)
MDP 的定义
马尔可夫决策过程 (Markov Decision Process, MDP) 是强化学习的数学框架,用于描述序贯决策问题。
一个 MDP 由五元组定义:
$$ \mathcal{M} = (S, A, P, R, \gamma) $$
| 符号 | 名称 | 说明 |
|---|---|---|
| $S$ | 状态空间 (State Space) | 所有可能状态的集合 |
| $A$ | 动作空间 (Action Space) | 所有可能动作的集合 |
| $P$ | 状态转移概率 | $P(s’ \mid s, a)$:在状态 $s$ 执行动作 $a$ 后转移到 $s’$ 的概率 |
| $R$ | 奖励函数 | $R(s, a, s’)$:状态转移的即时奖励 |
| $\gamma$ | 折扣因子 | $\gamma \in [0,1]$:未来奖励的折现率 |
马尔可夫性质
马尔可夫性质:当前状态已知的情况下,下一时刻状态只与当前状态相关,而与历史无关。
$$ P(s _{t+1} \mid s_t, a_t, s _{t-1}, a _{t-1}, \dots) = P(s _{t+1} \mid s_t, a_t) $$
直观理解:当前状态 $s_t$ 包含了做决策所需的全部信息。
轨迹与回报
轨迹 (Trajectory):一次完整的状态 - 动作序列
$$ \tau = (s_0, a_0, s_1, a_1, s_2, a_2, \dots) $$
回报 (Return):轨迹的累积折扣奖励
$$ G_t = \sum _{k=0} ^{\infty} \gamma ^k r _{t+k} = r_t + \gamma r _{t+1} + \gamma ^2 r _{t+2} + \dots $$
折扣因子的作用:
- $\gamma = 0$:只关心眼前利益
- $\gamma \to 1$:考虑长远利益
- 数学上保证无限时域回报有界
核心概念
策略 (Policy)
策略 $\pi$ 是智能体的行为准则,定义了在每个状态下如何选择动作。
| 类型 | 数学形式 | 说明 |
|---|---|---|
| 确定性策略 | $a = \pi(s)$ | 状态 $s$ 下总是选择同一动作 |
| 随机性策略 | $\pi(a \mid s)$ | 状态 $s$ 下选择动作 $a$ 的概率 |
价值函数 (Value Function)
状态价值函数 $V^\pi(s)$:从状态 $s$ 开始,遵循策略 $\pi$ 的期望回报
$$ V^\pi(s) = \mathbb{E} _\pi\left[G_t \mid s_t = s\right] = \mathbb{E} _\pi\left[\sum _{k=0} ^{\infty} \gamma ^k r _{t+k} \mid s_t = s\right] $$
动作价值函数 (Q 函数) $Q^\pi(s, a)$:在状态 $s$ 执行动作 $a$ 后,遵循策略 $\pi$ 的期望回报
$$ Q^\pi(s, a) = \mathbb{E} _\pi\left[G_t \mid s_t = s, a_t = a\right] $$
贝尔曼方程 (Bellman Equation)
贝尔曼方程描述了价值函数的递归结构:
状态价值的贝尔曼方程:
$$ V^\pi(s) = \sum_a \pi(a \mid s) \sum _{s’} P(s’ \mid s, a) \left[R(s, a, s’) + \gamma V^\pi(s’)\right] $$
Q 函数的贝尔曼方程:
$$ Q^\pi(s, a) = \sum _{s’} P(s’ \mid s, a) \left[R(s, a, s’) + \gamma \sum _{a’} \pi(a’ \mid s’) Q^\pi(s’, a’)\right] $$
最优价值函数
最优状态价值函数:
$$ V^*(s) = \max_\pi V^\pi(s) $$
最优动作价值函数:
$$ Q^*(s, a) = \max_\pi Q^\pi(s, a) $$
贝尔曼最优方程:
$$ V^(s) = \max_a \sum _{s’} P(s’ \mid s, a) \left[R(s, a, s’) + \gamma V^(s’)\right] $$
$$ Q^(s, a) = \sum _{s’} P(s’ \mid s, a) \left[R(s, a, s’) + \gamma \max _{a’} Q^(s’, a’)\right] $$
强化学习算法分类
分类图谱
mindmap
root((强化学习算法))
基于价值
Q-learning
SARSA
DQN
基于策略
REINFORCE
Policy Gradient
TRPO
PPO
Actor-Critic
A2C/A3C
SAC
TD3
基于模型
动态规划
蒙特卡洛树搜索
模型学习
1. 基于价值的方法 (Value-based)
核心思想:学习价值函数(Q 函数),通过价值函数导出策略。
$$ \pi(s) = \arg\max_a Q(s, a) $$
代表算法:
- Q-learning:离线时序差分学习
- SARSA:在线时序差分学习
- DQN:深度 Q 网络(用神经网络近似 Q 函数)
特点:
- ✅ 样本效率较高
- ✅ 适用于离散动作空间
- ❌ 难以处理连续动作空间
2. 基于策略的方法 (Policy-based)
核心思想:直接学习并优化策略函数 $\pi(a \mid s; \theta)$。
$$ \max _\theta J(\theta) = \mathbb{E} _{\tau \sim \pi _\theta}\left[\sum _{t=0} ^T \gamma ^t r_t\right] $$
策略梯度定理:
$$ \nabla _\theta J(\theta) = \mathbb{E} _{\tau \sim \pi _\theta}\left[\sum _{t=0} ^T \nabla _\theta \log \pi _\theta(a_t \mid s_t) Q^\pi(s_t, a_t)\right] $$
代表算法:
- REINFORCE:蒙特卡洛策略梯度
- TRPO:信赖域策略优化
- PPO:近端策略优化
特点:
- ✅ 适用于连续动作空间
- ✅ 可学习随机策略
- ❌ 样本效率较低
3. Actor-Critic 方法
核心思想:结合基于价值和基于策略的方法。
Actor (策略网络) ──→ 选择动作 a
│
▼
Critic (价值网络) ──→ 评估动作好坏
更新规则:
- Actor:根据 Critic 的评估更新策略
- Critic:学习价值函数
代表算法:
- A2C/A3C:同步/异步优势 Actor-Critic
- SAC:软 Actor-Critic(最大熵 RL)
- TD3:双延迟深度确定性策略梯度
特点:
- ✅ 样本效率高
- ✅ 适用于连续控制
- ✅ 训练稳定
4. 基于模型的方法 (Model-based)
核心思想:学习环境的动力学模型,然后基于模型进行规划。
$$ s _{t+1} = f(s_t, a_t; \theta _{model}) $$
方法分类:
| 方法 | 说明 |
|---|---|
| 已知模型 | 使用已知的物理模型(如机器人动力学) |
| 学习模型 | 用神经网络学习状态转移函数 |
| 模型学习 + 规划 | 学习模型后用 MPC 等方法规划 |
代表算法:
- MBPO:基于模型的策略优化
- MuZero:学习隐式模型 + 蒙特卡洛树搜索
特点:
- ✅ 样本效率最高
- ✅ 可“想象“未来
- ❌ 模型误差影响性能
关键要点总结
MDP 基础
- 状态、动作、转移概率、奖励、折扣因子
- 策略 $\pi$:状态到动作的映射
- 价值函数 $V^\pi, Q^\pi$:评估状态/动作的好坏
- 贝尔曼方程:价值函数的递归分解
- 最优价值函数:$V^, Q^$ 满足贝尔曼最优方程
算法分类
| 类别 | 代表算法 | 适用场景 |
|---|---|---|
| 基于价值 | DQN | 离散控制 |
| 基于策略 | PPO, TRPO | 连续控制 |
| Actor-Critic | SAC, TD3 | 连续控制 + 高效率 |
| 基于模型 | MBPO | 样本效率优先 |
与其他章节的关系
- Policy Based 算法 - 详细推导策略梯度
- Value Based 算法 - 详细推导价值函数
- A3C - Actor-Critic 方法详解
background
深度学习一次迭代的三个步骤
- 环境 -> 机器:state
- 机器 -> 环境:action
- 环境 -> 机器:reward
定义:
一轮迭代 = state -> action -> reward。 如果没有反馈,reward = 0。
一episode = 一局游戏,有赢/输结果的。
目标:maximize the expected cumulative reward per spisode。
监督学习 VS 强化学习
监督学习:从数据(State, Action)学习,学习的好坏取决于数据(State, Action)的好坏,因此需要大量数据。
强化学习:根据自己的(State, Action)经验学习,因此需要大量的经验。
强化学习的难点
- reward delay
- 有些Action没有reward,甚至可能有牺牲。但它对帮助得到reward有重要贡献。
- 需要Machine探索未尝试过的行为。
算法分类
- policy based算法 — 学actor
- value based算法 — 学critic
- policy + value 算法 — A3C算法
Alpha GO = polocy based + value based + model based
model based算法主要用于棋类游戏
应用
应用于下棋
生成两个agent,互相对弈,以胜负作为reward。
应用于Chat-Bot
生成两个agent,互相对话。
另外训练一个NN用于判断talk的好坏,并给予reward。
应用于电子游戏
Gym:https://gym.openai.com/
Universe:https://openai.com/blog/universe/
Policy Based 方法
Policy Based 方法直接学习策略函数$\pi$,用于选择动作。
Basic Version
公式改进
off-policy
近端优化策略
Value Based 方法
Value Based 方法学习价值函数(如 Q 函数),通过价值评估来间接学习策略。
value function
Q-Learning
Q-Learning 的改进算法
Q-Learning Vs Policy Based
Q-Learning比policy gradient好train,因为:
只要学到Q function,就能得到一个比较好的policy。
Q-Learning的缺点是:难以处理action是continuous的情况。
什么时候action是连续的?
答:例如开车,action可以是方向盘转多少度。
continuous action对Q-Learning有什么问题?
答:Q-Learning的一个步骤是求解:
$$
a = \arg\max_a Q(s, a)
$$
但a无法穷举
解决方法
- sample一组action
缺点:这样得到的Action不会太精确 - 用gradient ascend来解a的最优化问题
缺点:这样运算量大,且会遇到local minima的问题。 - 对$Q^\pi$这个NN做特别的设计,使得容易计算最优化问题

$$ \begin{aligned} Q(s, a) = -(a-\mu(s))^\top\sum(s)(a-\mu(s)) + V(s) \ \mu(s) = \arg\max_a Q(s,a) \end{aligned} $$
A3C 算法
A3C (Asynchronous Advantage Actor-Critic) 是结合了 Policy Based 和 Value Based 的算法。
复习
A3C
Pathwise Derivative Policy Gradient
强化学习补充主题
RL vs 轨迹优化
核心对比
| 维度 | 轨迹优化 | 强化学习 |
|---|---|---|
| 输出 | 一条轨迹 $(\mathbf{x}, \mathbf{u})$ | 一个策略 $\pi(\mathbf{s})$ |
| 泛化能力 | ❌ 仅适用于该轨迹 | ✅ 可处理新状态 |
| 训练时间 | 秒级 ~ 分钟级 | 小时级 ~ 天级 |
| 推理速度 | N/A | 毫秒级 |
| 模型需求 | ✅ 需要精确模型 | ⚠️ 可有可无 |
| 样本效率 | ✅ 高 | ❌ 低 |
方法选择决策树
开始:选择角色控制方法
│
├─ 是否需要泛化能力?
│ ├─ 否 → 轨迹优化 ⭐
│ └─ 是 → 强化学习 ⭐
│
├─ 是否有精确动力学模型?
│ ├─ 是 → MPC / 轨迹优化
│ └─ 否 → 强化学习
│
└─ 实时性要求?
├─ 毫秒级 → 强化学习(推理)
└─ 秒级可接受 → MPC
RL 在 3D 角色动画中的应用
DeepMimic 范式
核心思想:用强化学习模仿参考动作(来自动捕或轨迹优化)。
参考轨迹 (动捕/轨迹优化)
↓
奖励函数设计(跟踪误差 + 风格项)
↓
RL 训练(PPO/TRPO)
↓
泛化策略 π
奖励函数设计:
$$ r_t = w_{pose} \cdot r_{pose} + w_{vel} \cdot r_{vel} + w_{com} \cdot r_{com} + w_{end} \cdot r_{end} $$
| 奖励项 | 说明 |
|---|---|
| $r_{pose}$ | 姿势跟踪奖励(关节角度) |
| $r_{vel}$ | 速度跟踪奖励 |
| $r_{com}$ | 质心跟踪奖励 |
| $r_{end}$ | 终止奖励(摔倒惩罚) |
代表工作:
- DeepMimic (2018):开创性工作,模仿多样化动作
- AMP (2021):无参考姿态的对抗模仿学习
- ASE (2022):环境交互的技能学习
状态空间设计
典型的角色状态表示:
$$ s_t = (q_{root}, \dot{q}{root}, q{local}, \dot{q}{local}, q{ref}, \dot{q}_{ref}) $$
| 分量 | 说明 |
|---|---|
| $q_{root}$ | 根节点位置和旋转 |
| $\dot{q}_{root}$ | 根节点速度 |
| $q_{local}$ | 局部关节角度 |
| $\dot{q}_{local}$ | 局部关节角速度 |
| $q_{ref}$ | 参考姿势 |
| $\dot{q}_{ref}$ | 参考速度 |
动作空间设计
| 类型 | 说明 | 适用场景 |
|---|---|---|
| 关节位置目标 | 输出目标关节角度,用 PD 控制跟踪 | 最常用,平滑稳定 |
| 关节力矩 | 直接输出关节力矩 | 精确控制,但难训练 |
| 肌肉激活 | 输出肌肉激活信号 | 生物力学仿真 |
实践建议
训练技巧
| 技巧 | 说明 |
|---|---|
| 课程学习 | 从简单任务开始,逐步增加难度 |
| 奖励塑形 | 设计稠密奖励,加速学习 |
| 域随机化 | 随机化物理参数,提高泛化性 |
| 并行采样 | 多环境并行采样,提高样本效率 |
常见陷阱
| 陷阱 | 症状 | 解决方案 |
|---|---|---|
| 奖励黑客 | 智能体找到奖励漏洞 | 仔细设计奖励函数 |
| 欠训练 | 策略不稳定、易摔倒 | 增加训练步数 |
| 过拟合 | 只在特定场景有效 | 域随机化、增加多样性 |
| 稀疏奖励 | 学习缓慢或不收敛 | 奖励塑形、课程学习 |
相关链接
- 轨迹优化方法对比 - GAMES105 中的轨迹优化章节
- DeepMimic 论文笔记
- AMP 论文笔记
稀疏奖励 Sparse Reward
指大多数情况action没有reward的游戏。
Reward Shaping
developer自己设计一些reward来引导agnet
这些reward不是来自环境真正的reward。
根据游戏设计
缺点:需要domain knowledge
Curiosity Reward

ICM = intrinsic curiosity module
ICM根据(s1, a1, s2)计算出$r1^i$
$$
R(\tau) = \sum(r_t + r_t^i)
$$
ICM的设计

- Network1根据at和st预测$\hat s_{t+1}$
- 比较$\hat s_{t+1}$和$s_{t+1}$
- diff越大,$r_t^i$越高
即:
action越无法预测,action的reward越大。(鼓励冒险)
存在的问题:
some states is hard to predict, but not important。
例如:风吹草动。
机器不能什么都不做只是站着看风吹草动。
ICM改进版
增加feature extraction

feature extraction通过Network2实现,用于把state中没有意义的东西去掉。
N2的训练方法为:根据$\hat s_{t+1}$和$s_{t+1}$预测$\hat a_t$
Curriculum Learning
给机器的学习做规划,labelled data由简单到难
Hierarchial Reinforcement Learning
模仿学习 Imitation Learning
使用场景:
机器无法从环境中得到reward,只能看expert的demonstration
例如chatbot,难以决定聊得好不好,但可以收集很多人的真实对话。
Behavior Cloning
基于expert收集labelled data,把它当作监督学习来做.
存在的问题:
- Experts only samples limited observation

例如开车,expert不会把车开始左上角,所以永远sample不到处于左上角的data。
解决方法:data aggregation - agent会学习expert的一些与action不相关的个人习惯
- Training data和Testing data不match
Innverse Reinforcement Learning — IRL
RL:
根据Env和Reward选择Optimal Action
IRL:
先根据expert和Env反推reward,再根据reward和Env选择Optimal Action。
为什么要反推reward function?
答:Modeling reward可能很简单。简单的reward function可以导出复杂的policy。
framework of IRL:
-
expert $\hat \pi$与游戏互动得到的N个sample $\hat \tau$
-
Actor $\pi$与游戏互动得到的N个sample $\tau$
-
先验假设:$\hat \tau$是最棒的,$\hat \tau$的分数一定高于$\tau$
-
学习一个reward function使得:
$$ \sum R(\hat \tau_n) > \sum R(\tau_n) $$ -
用reward function + RL找actor $\pi’$

-
用$\pi’$代替$\pi$,进入下一个迭代
RAN Vs. IRL

什么是异常侦测
训练数据:
- normal data: ${x^1, x^2, …, x^N}$
- anomaly data:${\tilde x^1, \tilde x^2, …, \tilde x^N}$
输入:x
输出:x与训练集是否相似 normal/anomaly
应用
欺诈侦测(盗刷卡)、网络入侵侦测、癌细胞侦测
训练方法
是否能当成是二分类问题来训练?
答:不能,因为
- 除了normal都是anomaly,不能把各种anomaly归成一类,也很难穷举其类别
- 很多情况下,不容易收集anomaly的资料
应该怎样学习?根据data分为三种情况:
- labelled data — open-set recognition
- unlabelled data && all data normal
- unlabelled data && 有少量anomaly data,但不知道是哪些
假设数据都是labelled data。
label包含data是normal还是anomaly。
如果是normal,具体又是normal中的哪一类。
训练

-
训练集:全部都是normal data,$\hat y$是normal类别的分类
把normal data当作多分类问题来训练,同时输出类别和对分类的置信度。 -
验证集:样本有normal和anomaly的data,并有label来区别是normal还是anomaly。
根据performance来决定$\lambda$以及其它超参数。
$$ x = \begin{cases} \text{normal} && , c(x) > \lambda \ \text{anomaly} && , c(x) \le \lambda \end{cases} $$ -
测试集:输入样本,根据公式判断normal/anomaly
Evaluation
如何根据performance判断模型的好坏?是否能用准确率?
答:不能。
异常侦测问题中,异常数据可能非常少,属于极度偏斜的数据。这种情况下不适合使用正确率。
将数据制作成confusion matrix,例如:
| Anomaly | Normal | |
|---|---|---|
| Detected | 1 | 1 |
| Not Detected | 4 | 99 |
左下角的数据为“异常data被判断为正常”的错误,又叫“missing”
右上角的数据为“正常data被判断为异常”的错误 ,又叫“false alarm”
$\lambda$取不同的值会得到不同的confusion matrix,哪种模型更好取决于对不同错误的cost的定义。
data中大部分是normal,有少量的anomaly。但都是unlabelled,不哪个是anomaly。
为什么跳过Case 2?因为实际场景都case 3,即使你认为是data都是clear的,但也有可能其实是polluted,只是你不知道而已。
方法一:概率统计
-
定义概率密度函数为$f_\theta(x)$
这个函数由参数$\theta$决定f(x)的形状。
$\theta$可以是一个值或一个向量,是向量代表有多个参数。
$\theta$未知,要根据x求出$\theta$,从而决定了f(x)的形状。
$f_\theta(x)$通常使用多维高斯分布。 -
定义对数似然函数
$$ L(\theta) = \log \left[ f_\theta(x^1)f_\theta(x^2)\cdots f_\theta(x^N) \right] $$ -
求得到最大对数似然的$\theta$
$$ \theta^* = \arg\max_\theta L(\theta) $$
方法二:auto-encoder
把x转成code再还原成$\hat x$
x与$\hat x$越接近,说明x越正常
其它方法
one-class SVM, isolated forest
对抗模型
对抗模型研究如何攻击和防御机器学习模型。
对抗模型,要对抗的是:
- 噪音
- human制造出来的有恶意的攻击
什么是攻击
输入正常的x0,NN会得到正确的结果
但通过经心设计$\Delta x$,使得NN会在$x+\Delta x$上犯错,而人类无法分辨$x+\Delta x$和x。
怎样攻击
- 正常训练

$$ L(\theta) = C(y^0, y^{\text{true}}) $$
x是固定的,调整$\theta$
- 无目标攻击

$$ L(x’) = - C(y’, y^{\text{true}}) $$
$\theta$是固定的,调整x
- 有目标攻击

$$ L(x’) = - C(y’, y^{\text{true}}) + C(y’, y^{\text{false}}) $$
- 额外限制
$$ d(x^0, x’) \le \epsilon $$
不要被发现
d是怎么定义的?
图像应用上,L-infinity比L2-norm更合适
怎样求解x
方法一:梯度下降法
$$ \begin{aligned} x^* = \arg\min_{d(x^0, x’) \le \epsilon} L(x’) \end{aligned} $$
这是一个带限制的最优化问题
-
将x’初始化为x0
-
用梯度下降法更新xt
$$ x^t = x^{t-1} - \eta \nabla L(x^{t-1}) $$ -
增加限制
如果{d(x^0, x’) > \epsilon},则xt = fix(xt)
方法二:FGSM
Fast Gradient Sign Method
$$ \begin{aligned} x^* = x^0 - \epsilon \Delta x \ \Delta x = \text{sign} (\frac{\partial L}{\partial x’}) \end{aligned} $$

直观解释:
FGSM不在意$\Delta x$的值,只在意它的方向
例如$\Delta x$指向左右任意一个方向,x*都会走到右上角
可以看任是一个LR巨大的一次GD
White Box VS Black Box
白盒攻击 - 知道NN的参数
以上方法都是白盒攻击
黑盒攻击 - 不知道NN的参数,有NN的训练集
- 用training data训练一个NN proxy
- 用白盒攻击方法找到能攻击NN proxy的图像
- 用这张图像去攻击NN
黑盒攻击 - 不知道NN的参数,没有NN的训练集
- 用自己的training data喂NN,得到output
- 用自己的training data + NN的output得到labelled data
- 用labelled data训练NN proxy
- 用白盒攻击方法找到能攻击NN proxy的图像
- 用这张图像去攻击NN
其它攻击方法
Universal Adversal Attack
不是针对某个样本制作攻击
制作一张通过的$\Delta x$图像
这张图像叠加到任意图像上都有攻击作用
可以用于white或者black
Adversarial Reprogramming
通过攻击改变一个NN的功能
passive defense 被动防御
不改变model,增加一个Anomaly Detection
增加一个filter,例如smoothing

Feature Squeeze

Randomization at Inference Phase

缺点
如果防御机制泄漏,攻击仍会生效
Proactive Defence 主动防御
Training a model that is robust to adversarial attack
找出漏洞,补起来
根据图像攻击算法,找到攻击图像,把攻击图像当作训练样本来训练
缺点
训练时只能列举有限的攻击算法,换用算法攻击,仍然能攻破
例如ML将一张图分类为猫,同时要回答:
- 为什么你认为这是一只猫? — Local Explanation
- 你认为一只猫是怎样的? — Global Expanation
Local Explanation
方法一:
将Object x分解成Component (x1, x2, …, xN)
移除一个compenent之后,对decision的影响越大,说明这个component越重要。
一个component可以是一个pixel、segment、方块、单词,或是自己定义的一个单位。
component的大小必须很小心地设计,太大或太小都得不到好的结果
方法二:Saliency Map
对输入向量x的一个分量增加一个小小的扰动$\Delta x$,得到:
$$
(x_1, x_2, \cdots, x_n, \cdots, x_N) \rightarrow (x_1, x_2, \cdots, x_n+\Delta x, \cdots, x_N)
$$
x的一个分量通常是一个像素。
由于x的改变,y也会相应地改变:
$$
y \rightarrow y + \Delta y
$$
计算$|\frac{\Delta y}{\Delta x}|$,值越大,说明x的这个分量越重要。
缺点:Gradient Sturation
$$
|\frac{\Delta y}{\Delta x}| = |\frac{\partial y}{\partial x}|
$$
但在某个位置梯度小不代表它不重要。
方法三:用一个model解释另一个model LIME
LIME = Local Interpretable Agnostic Explanations
basic Idea:
用一个有解释能力的model(例如Linear)去模仿另一个没有解释能力的model(例如NN)
但是,Linear Model不可能真的能模拟出NN,只能模拟出NN的一个local region
问:怎样fit with linear model?
答:提取图像的m个特征,定义linear model为:
$$
y = w_1x_1 + w_2x_2 + \cdots + w_mx_m + b
$$
问:怎么基于linear model解释?
$w_m \approx 0 \Rightarrow x_m$与结果无关
$w_m > 0 \Rightarrow x_m$对结果起积极作用
$w_m < 0 \Rightarrow x_m$对结果起消极作用
Global Explanation
Activation Maximization
$$ x^* = \arg\max_x y_i $$
其中yi为期望的结果的confidence
这种方法还需要增加一些额外的限制,否则结果不好
Image Geneator
例如 GAN、VAE
$$
x^* = \arg\max_x y_i \Rightarrow z = \arg\max_z yi, x = G(z)
$$
用同一个模型,持续地学习
Knowledge Retention, but not intransigence
Catastropic Forgetting
例如有task 1和task 2:
如果同时学task 1和task 2,两个都能学好:
如果先学task 1,再学task 2,task 1会忘掉,这种遗忘称为:
Elastic Weight Consolidation (EWC)
Basic Idea:
model中某些参数对prev task特别重要,训练新task时只改变不重要的参数。
$$
L’(\theta) = L(\theta) + \lambda \sum_i b_i(\theta_i - \theta^b_i)^2
$$
其中:
$\theta^b_i$:上一个Task的参数,在这个task中当作常数看待。
$\theta_i$:这个Task要调的参数
$b_i$:$\theta^b_i$的gurad,代表了$\theta^b_i$的重要性。
第一项:学好新task
第二项:与旧Task的参数差别不要太大。
$b_i=0$:$\theta^b_i$无保护,$\theta_i$随意发挥
$b_i=\inf$:$\theta^b_i$强保护,$\theta_i$必须等于$\theta^b_i$
问:为什么会发生Catastropic Forgetting?
答:
问:怎么定义bi?
答:$\theta^b$肯定位于谷底。$\theta^b$的二次微分代表$\theta^b$在这个方向的谷底是宽是窄。
越平坦说明$\theta^b_i$的改动影响越小,越不需要保护。$b_i$就越小。
为什么EWC有用?
答:
Generating Data
Multi-Task虽然可以解决LLL的问题,但缺点是需要存储大量的training data。
可以训练一个能生成training data的NN,这样只存一个NN就可以了。
knowledge Transfer
问:为什么不“每个task各训练一个model”?
答:1.不同task之间学到的东西无法迁移。2,存不下那么多模型。
问:LLL和transfer learning有什么区别?
答:TL只要求task 1的学习对Task 2有帮助。LLL进一步要求task 2的学习不会导致遗忘task 1,甚至希望能有助于task 1。
评价LLL的好坏(Evaluation)
填表

$R_{i,j}$:训练过task [1 .. i]之后,task j的测试效果。
- i < j,$R_{i,j}$代表task i transfer到task j的效果。
- i > j,$R_{i,j}$代表task j对task i的影响
定义衡量指标
$$ \begin{aligned} \text{Accuracy} = \frac{1}{T} \sum_{i=1}^T R_{T,i} \ \text{Backward Transfer} = \frac{1}{T-1}\sum_{i=1}^{T-1} (R_{T,i} - R_{i,i}) \ \text{Forward Transfer} = \frac{1}{T-1}\sum_{i=2}^{T} (R_{i-1,i} - R_{0,i}) \end{aligned} $$
GEM — Gradient Episodic Memory
一种让backward为正的方法。
正常情况下,Backward Transfer < 0 — 遗忘
GEN算法效果,Backward Transfer > 0 — 触类旁通、知识迁移
- 计算:
g: current task的梯度方向
gi:之前的task i的梯度方向 - 判断
g * gi > 0 ==> g’ = g
g * gi < 0 ==> 调整g’,使g’ * gi > 0 且 g和g’尽量接近 - 更新
基于g’更新
Model Expansion, but Parameter Efficiency
Progressive Neural Networks

Expert Gate

Net2Net

前两种方法每次有新的Task就要扩展模型,参数的增加速度与task成正比
第三种只在当前模型难以提升时才增加结点
Curriculum Learning
还是上面例子中的task1和task 2
如果先学task 1,再学task 2,task 1会忘掉
如果先学task 2,再学task 1,task 2不会忘掉
说明task的顺序很重要。怎样排序最合适?
Meta Learning = Learn to Learn
什么是Meta Learning?
LLL与Meta Learning的关系?
同:学过很多task之后,期待在新的task上会学得更好
异:LLL是让同一个model学会所有的task。Meta Learning是让Model学会学习的能力。
什么是Mechine Learning?
- 定义一个F(mechine learning algorithm),输入大量训练数据,输出一组参数f*
- 基于参数f*,输入testing data,输出预测结果
Mechine Learning是一种找f的能力。
Meta Learning是一种找F的能力。
Meta Learning的步骤:
-
定义一组learning algorithm F 图是的红框原本都是人工设计出来的。选择不同的设计就是不同的F。
-
评价一个F的好坏

$$ L(F) = \sum_{n=1}^N l^n $$ -
找到最好的F
MAML
Model Agnostic Meta-Learning
只关注“初始化参数”

$$
\begin{aligned}
L(\phi) = \sum_{n=1}^N l^n(\hat \theta^n) \
\phi = \phi - \eta \nabla_{\phi} L(\phi)
\end{aligned}
$$

横轴:model参数
纵轴:loss
$\phi$参数可能在task 1和task 2上效果一般,
但是从$\phi$出发,
在task 1上能容易地找到最优参数$\hat \theta^1$,
在task 2上能容易地找到最优参数$\hat \theta^2$,
因此$\phi$是一个好的初始化参数。

这个$\phi$不是一个好的初始化参数,因为它会导致task 2收敛不到最小。
MAML假设:
最后得到一个比较好的初始化参数$\phi$以后,只需经过一次gradient descent,就能找到最好的$\hat \theta$。
以下是推导公式:
$$
\begin{aligned}
\hat \theta = \phi - \epsilon \nabla_{\phi} l(\phi) \
L(\phi) = \sum_{n=1}^N l^n(\hat \theta^n) \
\phi = \phi - \eta \nabla_{\phi} L(\phi) \
\nabla_{\phi}L(\theta) = \sum_{n=1}^N \nabla_\phi l^n(\hat \theta ^n) \
\nabla_{\phi} l(\hat \theta) = \frac{\partial l(\hat \theta)}{\partial \theta_i} = \sum_j \frac{\partial l(\hat \theta)}{\partial hat \theta_j} \frac{\partial hat \theta_j}{\partial \theta_i} \approx \frac{\partial hat \theta_j}{\partial hat \theta_i} = \nabla_{\hat\theta}l(\hat \theta)
\end{aligned}
$$

Reptile

